В предыдущей статье я подробно рассмотрел как выглядит внутреннее устройство embedding. Там же рассмотрен один из способов использования Gensim embedding word2vec.
В этой статье рассмотрю второй способ встраивания слоя embedding в нейронную сеть. Embedding, помимо уменьшения требований к памяти, ценен тем, что в отличие от Bag Of Words (BOW) позволяет учитывать последовательность слов в предложении.
Напомню, второй способ состоит в том, чтобы для индексов полученных токенизатором, например, Keras-а, поменять веса в матрице embedding-а так, чтобы индекс определенного слова в embedding-е соответствовал индексу слова после токенизатора:
- Получить массив индексов с помощью Tokenizer. В этом случае словарь упорядочен по частоте появления слов в тексте, поэтому можно обрезать словарь с конца если нужно получить укороченный вариант словаря.
- Получить предобученный embedding (обучить самому или скачать готовый).
- Адаптировать матрицу весов слоя embedding таким образом, чтобы индексу определенного слова после Tokenizer-а в слое embedding соответствовало то-же слово из словаря embedding-а.
Я не буду подробно рассматривать загрузку и преобработку текстов. Эти моменты подробно разобраны в статьях «Анализ авторства текста полносвязной нейронной сетью в Keras» и «Разметка текста для обучения нейронной сети«.
Предположим тексты авторов подгружены в массив writers_text. Для самостоятельного обучения word2vec embedding-а объединим тексты в один большой документ:
all_writers_text = " ".join(writers_text)
print("Длина всех текстов:", len(all_writers_text))
all_writers_text[:300]Далее необходимо создать массив предложений, разделив (split(‘\n’)) текст по символу возврата коретки «\n».
writers_x_train_all = all_writers_text.split("\n")
writers_x_train_all = [line.strip() for line in writers_x_train_all if line.strip() != ""] #уберем пустые предложения
print(writers_x_train_all[:20])Получим следующую последовательность:
['\ufeffДон Кихот', 'ДЕЙСТВУЮЩИЕ ЛИЦА', 'Алонсо Кихано, он же Дон Кихот Ламанчский.', 'Антония – его племянница.', 'Ключница Дон Кихота.'...]
Отмечу, что если в качестве текста выступали отзывы и разметка была как в статье «Разметка текста для обучения нейронной сети«, то деление может производится не по предложениям, а по отзывам. Это важно, если нужно определить окраску конкретного отзыва, а не авторство текста.
Далее я рассмотрю два способа подготовки разбитого на предложения/параграфы текста.
Подготовка текста для word2vec с помощью NLTK или Keras
В NLTK есть необходимые для предобработки текст функции. Загрузим необходимые функции:
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import nltk
import string
nltk.download('punkt')
nltk.download('stopwords')Со стопсловами нужно быть осторожными, поскольку в NLTK добавлено довольно большое количество стопслов. В некоторых случаях удаление такого количества слов может сказаться на качестве обучения.
russian_stopwords = ['и', 'в', 'а', 'с', 'но', 'у', 'я', 'же'] #укороченная последовательность стопслов
#russian_stopwords = set(stopwords.words('russian')) #результат может ухудшаться
print(russian_stopwords)Функция для преобразования списка предложений в очищенный от лишних слов список предложений и разбитый по словам:
def textToList(text):
review_lines = list()
for line in text:
if line.strip() != "":
tokens = word_tokenize(line)
tokens = [w.lower() for w in tokens] #приводим Case к нижнему регистру
table = str.maketrans('', '', string.punctuation)
stripped = [w.translate(table) for w in tokens]
words = [word for word in stripped if word.isalpha()] #убираем токены, которые не являются символами
words = [w for w in words if not w in russian_stopwords]
if (len(words) > 0):
review_lines.append(words)
return review_lines Запускаем на текстах авторов:
writers_lines = textToList(writers_x_train_all) print(writers_lines) len(writers_lines)
[['дон', 'кихот'], ['действующие', 'лица'], ['алонсо', 'кихано', 'он', 'дон', 'кихот', 'ламанчский'], ['антония', 'его', 'племянница'], ['ключница', 'дон', 'кихота'], ['санчо', 'панса', 'оруженосец', 'дон', 'кихота'], ['перо', 'перес', 'деревенский', 'священник', 'лиценциат'], ...]] 88469
На Keras-е код будет немного лаконичнее:
from keras.preprocessing.text import text_to_word_sequence
def processText(text_list):
tokens = [text_to_word_sequence(line, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n\ufeff????????????☝️?✌️?????♂️♂️?????♂️‼️♥❤️??????????????????????', lower=True, split=' ') for line in text_list]
review_lines = list()
for words in tokens:
words = [w for w in words if w.isalpha()] #убираем токены, которые не являются символами
words = [w for w in words if not w in russian_stopwords] #убираем стопслова
review_lines.append(words)
return review_lines writers_lines = processText(writers_x_train_all) print(writers_lines) print(len(writers_lines))
[['дон', 'кихот'], ['действующие', 'лица'], ['алонсо', 'кихано', 'он', 'дон', 'кихот', 'ламанчский'], ['антония', 'его', 'племянница'], ['ключница', 'дон', 'кихота'], ['санчо', 'панса', 'оруженосец', 'дон', 'кихота'], ['перо', 'перес', 'деревенский', 'священник', 'лиценциат'], ['николас', 'деревенский', 'цирюльник'], ['альдонса', 'лоренсо', 'крестьянка'], ['сансон', 'карраско', 'бакалавр'],...] 88469
Создание модели Gensim Word2Vec
Создадим слой embedding, обучив модель Word2Vec на своих данных.
import gensim EMBEDDING_DIM = 100 w2v=gensim.models.Word2Vec(sentences = writers_lines, size = EMBEDDING_DIM, min_count = 1, window = 5)
- sentences — массив слов разбитых на слова (список списков токенов).
- size — размерность результирующего embedding вектора.
- min_count — помещать в словарь только слова встретившиеся в тексте более min_count раз.
- window — максимальное расстояние междутекущим и предсказанным словом в предложении. В модели word2vec для определения смысловой связи между словами просматриваются соседние слована расстоянии не более window.
При запуске строки происходит обучение модели. Если размер текста значительный, то можно использовать передачу данных в модель генератором. Пример здесь. В этом случае нужно разбивать подготовку и тренировку модели:
w2v = Word2Vec(min_count=1) w2v.build_vocab(sentences) # prepare the model vocabulary w2v.train(sentences = writers_lines, total_examples=w2v.corpus_count, epochs=20)
Для получения размера словаря word2vec:
words = list(w2v.wv.vocab)
print("Размер словаря", len(words))Для EMBEDDING_DIM = 100 вектор для слова «путешественник» будет:
writers_w2v['путешественник']
array([ 0.05081493, 0.12625282, 0.10422447, 0.22967575, -0.15767379,
-0.06992438, -0.01123928, 0.0363132 , 0.00124542, -0.14810537,
..................
0.05886971, 0.16386874, -0.02646038, -0.03813764, 0.02185517,
-0.01825876, -0.1485317 , -0.08367622, 0.06347819, 0.02548837],
dtype=float32)Можно посмотреть сходные слова:
writers_w2v.wv.most_similar('путешественник')
#Сходные слова по косинусному расстоянию c учетом векторных операций сложения и вычитания векторов для слов
writers_w2v.wv.most_similar_cosmul(positive=['путешественник'], negative=['мужчина']) #сложение и вычитание векторов и поиск близких по косинусной мереТокенизация текста
Разобъем исходный текст на токены (слова):
def tokenizeIt(review_lines):
num_words = 20000 #число слов, которые войдут в словарь частотности
print("Размер выборки:", len(review_lines))
tokenizer = Tokenizer(num_words=num_words, filters='!"#$%&()*+,-—./:;<=>?@[\\]^_`{|}~\t\n\xa0\ufeff????????????☝️?✌️?????♂️♂️?????♂️‼️♥❤️??????????????????????', lower=True, split=' ', char_level=False) #, oov_token='unknown'
tokenizer.fit_on_texts(review_lines) #формируем токены на основе частотности в нашем текст
sequences = tokenizer.texts_to_sequences(review_lines)
max_len = len(max(sequences, key = len)) #максимальная длина предложения (длина развернутой RNN сети)
word_index = tokenizer.word_index
num_words = len(tokenizer.word_index) + 1
print("Максимальная длина отзыва:", max_len, "слова.")
print("Уникальных токенов:", len(word_index))
print("Номер тестового слова:", word_index['водитель']) #Проверяем индекс выбранного слова
print("Кол-во слов:", num_words)
return max_len, num_words, sequences, word_index, tokenizermax_len, num_words, sequences, word_index, tokenizer = tokenizeIt(writers_lines) print(word_index) print(sequences)
Пример на отзывах:
Размер выборки: 4978
Максимальная длина отзыва: 302 слова.
Уникальных токенов: 15434
Номер тестового слова: 735
Кол-во слов: 15435
{'не': 1, 'на': 2, 'что': 3, 'это': 4, 'как': 5, 'тесла': 6, 'за': 7, 'то': 8, 'для': 9, 'по': 10, 'машина': 11, 'все': 12, 'очень': 13,...}
[[735, 6177, 22, 248, 19, 736], [317, 11, 70, 222], [6, 373, 3767, 22, 143, 507], [11, 2, 1138, 1289, 3768, 130, 577, 92, 2681, 792, 2091],...]Для подачи входной последовательности индексов после токенизатора на нейронку необходимо выровнять длину каждого предложения, добив нулями для masking-а до максимальной длины предложения max_len.
x_train_pad = pad_sequences(sequences = sequences, maxlen = max_len) #, padding='post', truncating='post') #все предложения длиной <max_len дополняем нулями в конце, >max_len - отбрасываем
print(x_train_pad[5])
print(x_train_pad[5].shape)
print("x_train shape:", x_train_pad.shape)[ 0 ..... 0 0 0 0 0 0 0
0 0 0 0 0 737 301 1742]
(302,)
x_train shape: (4978, 302)Формирование матрицы весов для embedding слоя
После токенизации текста нужно сформировать матрицу весов слоя embedding таким образом, чтобы слову с определенным индексом в словаре токенизатора соответствовало то-же слово.
Фактически нужно создать новую матрицу весов слоя где на позиции соответствующей индексу слова в словаре Tokenizer будет находится вектор соотвествующий этому-му же слову из словаря Word2Vec.
from keras.initializers import Constant
#Подготавливаем embedding слой для использования в модели
#В матрице embedding номер слова заменяется на вектор из модели word2vec
def getEmbeddingLayer(num_words, embedding_size, max_length, tokenizer, word2vec, Trainable = False):
print("Размер embedding матрицы:", num_words, "x", embedding_size)
embedding_matrix = np.zeros((num_words, embedding_size))
for word, i in tokenizer.word_index.items():
if i > num_words: #если индекс превышает кол-во слов в словаре, то скипаем
continue
embedding_vector = w2v[word] #получаем вектор соответствущий слову в модели word2vec
if embedding_vector is not None: #если слово отсутствует в словаре word2vec, то оно в матрице np.zeroes останется равным 0
embedding_matrix[i] = embedding_vector #если слово найдено в словаре токенизатора, то в embedding_matrix проставляем вектор соответствующий слову
embedding_layer = Embedding(input_dim = num_words,
output_dim = embedding_size,
embeddings_initializer = Constant(embedding_matrix),
input_length = max_length,
trainable = Trainable)
return embedding_layer, embedding_matrix Получаем слой для использования в качестве первого в модели нейронной сети.
writers_embedding_layer, writers_embedding_matrix = getEmbeddingLayer(num_words, EMBEDDING_DIM, max_len, tokenizer, writers_w2v, Trainable = False)
Разделим выборки на обучающую и проверочную. В исходном y_train 5 первых колонок в матрице отведено на multi-label classification c loss binary_crossentropy и активационной функцией ‘sigmoid’. Остальные 3 колонки — для анализа окраски текста (sentiment analysis) классификации с выбором одного из значений (categorical crossenropy и активация ‘softmax’). Подробнее в статье «Разметка текста для обучения нейронной сети«.
num_classes = 5 #Подготовка обучающей и проверочной выборки x_train_, x_test, y_train, y_test = train_test_split(x_train_pad, y_train_all, test_size = 0.2) #, random_state = 42) z_train = y_train[:, num_classes:8] z_test = y_test[:, num_classes:8] y_train = y_train[:, :num_classes] y_test = y_test[:, :num_classes]
Собираем модель нейронной сети:
def buildModel(embedding_layer): modelGRU = Sequential() #embedding_layer = w2v.wv.get_keras_embedding(train_embeddings=False) modelGRU.add(embedding_layer) #modelGRU.add(Embedding(num_words, embedding_size)) modelGRU.add(SpatialDropout1D(0.2)) modelGRU.add(Bidirectional(GRU(40, return_sequences=True))) modelGRU.add(Bidirectional(GRU(40))) #modelGRU.add(LSTM(8,return_sequences=True )) #modelGRU.add(LSTM(8)) modelGRU.add(Dropout(0.2)) modelGRU.add(Dense(64,activation = 'relu')) modelGRU.add(Dropout(0.2)) modelGRU.add(Dense(num_classes,activation = 'sigmoid')) modelGRU.summary() return modelGRU
Запускаем модель обучаться:
modelGRU = buildModel(embedding_layer) #modelGRU.compile(loss='binary_crossentropy', metrics=['accuracy'], optimizer=Adam(lr=1e-4)) modelGRU.compile(loss='binary_crossentropy', metrics=[AUC(name='auc')], optimizer=Adam(lr=1e-4)) historyGRU = modelGRU.fit(X_train, Y_train, batch_size=64, epochs=20, validation_data=(X_test, Y_test))
Проверка качества обучения
Эффективность обучения проверяется на
def plotHistory(history, acc = 'accuracy', val_acc = 'val_accuracy'):
plt.plot(history.history[acc], label='Доля верных ответов на обучающем наборе')
plt.plot(history.history[val_acc], label='Доля верных ответов на проверочном наборе')
plt.xlabel('Эпоха обучения')
plt.ylabel('Доля верных ответов')
plt.legend()
plt.show()После тренировки нейронки вызываем функцию, передав имя модели, метрики на обучающей и проверочной выборки для отображения.
plotHistory(historyGRU, 'auc', 'val_auc')
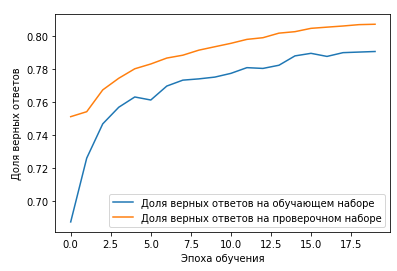
def getValidation(x_test, y_test, model_for_eval, batch_size):
# Вычисляем результаты сети на тестовом наборе
score, acc = model_for_eval.evaluate(x_test, y_test, verbose = 2, batch_size = batch_size)
print("Score: %.2f" % (score), '%')
print("Acc: %.2f" % (acc), '%')Для оценки точности предсказания на multi-label classification написал следующую функцию для подсчета процента верных ответов. Поскольку на выходе после sigmoid вектор с длиной class_name = 5 и в каждой позиции вероятность предсказанная моделью по наличию признака, то нужно задать некоторую границу выше которой будет считаться, что признак есть. В данном случае я задал threshold = 0.1. Все значения вероятности с большими значениями говорят о том, что признак в предложении присутствует.
def getPredQuality(x_test, y_test, model_for_pred, threshold = 0.1):
print("Кол-во строк:", x_test.shape[0])
pred_count = np.zeros(y_test.shape[1])
for p in range(len(pred_count)):
pred_count[p] = sum(y_test[:, p] == 1)
printSentimensCount(pred_count, "Кол-во отзывов ")
pred_precision = np.zeros(y_test.shape[1])
for x in range(len(x_test)): #range(10): #
y_pred = model_for_pred.predict(x_test[x].reshape(1, x_test.shape[1]), batch_size=1, verbose = 0)[0]
y_pred = 1 * (y_pred >= threshold) #Если значение в предсказании выше некоторого порога, то заменяем на 1
logical_and = 1 * np.logical_and(y_test[x], y_pred) #После логического AND на выходе массив с значениями равными 1, там где совпало
percentage = np.round((pred_precision / pred_count) * 100, 2)
print()
printSentimensCount(percentage, "Точность предсказания ")getValidation(X_test, Y_test, modelGRU, 32) getPredQuality(X_test, Y_test, modelGRU)
Пример результата multi-label classification:
32/32 - 3s - loss: 0.3795 - auc: 0.8071 Score: 37.95 % Acc: 80.71 % Кол-во строк: 996 Кол-во отзывов сравнение: 118.0 Кол-во отзывов дальность: 28.0 Кол-во отзывов эмоции: 362.0 Кол-во отзывов комфорт: 358.0 Кол-во отзывов скорость: 39.0 Точность предсказания сравнение: 92.37 Точность предсказания дальность: 0.0 Точность предсказания эмоции: 100.0 Точность предсказания комфорт: 100.0 Точность предсказания скорость: 0.0
Полезные ссылки
- https://towardsdatascience.com/another-twitter-sentiment-analysis-with-python-part-6-doc2vec-603f11832504
- https://towardsdatascience.com/machine-learning-word-embedding-sentiment-classification-using-keras-b83c28087456
- https://towardsdatascience.com/another-twitter-sentiment-analysis-with-python-part-11-cnn-word2vec-41f5e28eda74