Анализ текстовой информации — весьма полезный инструмент. Я ранее публиковал уже статьи на тему анализа текстов. Например, анализ авторства текста, генеративные сети с условием (в этих GAN-ах использовался слой embedding), чатботы и пр. Пора систематизировать способы представления текстов в числовой форме и попробовать понять что «под капотом», т.е. как это все работает.
One-hot encoding (OHE)
Самый простой подход :
- Выделить в исходном тексте split-ом все слова.
- Создать из них словарь.
- Закодировать слова с помощью 0 и 1 («one-hot»). Это не двоичное представление индекса слова в словаре, поскольку единица в векторе только одна, остальные — 0!
Например, есть текст «The cat sat on the mat». Чтобы представить каждое слово для обучения нейронной сети, создадим вектор из нулей с длиной равной размеру словаря. Единица будет на позиции соответствующей слову.

Чтобы создать вектор, который кодировал бы всю фразу достаточно объединить (concatenate) one-hot вектор каждого из слов. Очевидно, что при этом полностью теряется информация о последовательности слов в тексте. Остается только информация о наборе слов («bag of words»).
Подход крайне неэффективен. Слово закодированное с помощью one-hot кодирования — это гигантский (длина равна количеству слов в тексте) разреженный (sparse — большая часть 0 и в одной позиции 1-ца) вектор. Под него уходит очень много памяти.
Кодирование словаря уникальными индексами
Другой распространенный подход — кодировать каждое слово некоторым уникальным числом. В примере выше можно было-бы слову «cat» сопоставить с 1, 2-ку присвоить для «mat» и т.д.
В этом случае можно было-бы закодировать фразу «The cat sat on the mat» плотным (dense) вектором, скажем, [5, 1, 4, 3, 5, 2]. Этот подход эффективен с т.з. использования памяти.
Однако, этот подход имеет несколько минусов:
- Кодирование целыми числами не учитывает взаимосвязи между словами. Впрочем, one-hot encoding его тоже не учитывает.
- Нейронная сеть плохо воспринимает целочисленное кодирование. Для нейронки число сложно интерпретировать, они для неё все как-бы одинаковые. Собственно, поэтому при классификации, например, картинок в тестовой базе MNIST при обучении номер на картинке кодируется в OHE. Например, методами tokenizer-а Keras: to_categorical.
Чтобы нейронная сеть корректно воспринимала выходные значения представленные в числовом виде без предварительного кодирования в OHE используется специальная функция loss: sparse_categorical_crossentropy. Она работает только для выходных значений и вычисляет cross-entropy между реальными и предсказанными сетью значениями.
Bag Of Words
Кодирование входных данных в OHE приводит к серьезной проблемой с нехваткой памяти при обработке данных. Например, рассмотрим для примера задачу эмоционального анализа текстов (sentiment snalysis). Например, есть отзывы клиентов на продукт. Они могут быть положительные, отрицательные и нейтральные.
Типовой механизм преобразования текстов для обработки нейронной сетью будет следующим:
- Текст разбивается (split) на слова с параллельной очисткой от лишних символов. Например, используется токенизатор Keras:
tokenizer = Tokenizer(num_words=num_words, filters='!"#$%&()*+,-—./:;<=>?@[\\]^_`{|}~\t\n\xa0????????????☝️?✌️?????♂️♂️?????♂️‼️♥❤️?????????????????????', lower=True, split=' ', char_level=False) #, oov_token='unknown'- Словам в соответствие ставятся индексы (числовые значения):
tokenizer.texts_to_matrix(texts, mode='count')
- По умолчанию в токенизаторе параметр reserve_zero=True, поэтому первым элементом в матрице индексов будет стоять 0, зарезервированный в качестве значения для максирования (masking). Следующий слой нейронной сети должен понимать, что 0 — это не реальные данные, а искусственно дополненные. Полученная матрица индексов будет длиннее по горизонтали на 1.
- Предложения выравниваются по длине с помощью Keras pad_sequences, добавлением 0-ей в начале или конце массива (padding=’post’). Кроме того фраза может быть урезана по длине с начала или с конца (truncating=’post’).
x_train = pad_sequences(x_train_tokenized, maxlen=max_len) #, padding='post', truncating='post')
- Полученная матрица индексов, выровненная по длине преобразуется в OHE. На выходе получится гигантская разреженная матрица (sparse) заполненная 0-ми и лишь одной 1-ей, стоящей в позиции равной индексу слова. Это удобно, поскольку если взять argmax от такого вектора, то он вернет позицию в которой стоит 1, т.е. индекс слова.
- Каждому слову будет поставлен в соответствие вектор равный длине используемого словаря. Например, в обработанном тексте содержалось 20000 слов (словарь), соответственно, каждое слово будет представлено вектором длиной 20000.

Размерность полученной OHE матрицы:
- Максимальная длина фразы в отзывах — 500 слов. После pad_sequences все фразы в матрице будут длиной 500.
- Размер словаря — 20000 слов, те. каждое слово будет представлено вектором длиной 20000.
- Отзывов — 10000 шт.
OHE_shape = 500 * 20000 x 10000 = 10 000 000 x 10000.
Визуализация такого способа подачи текстового представления на нейронную сеть:

Исходная матрица подается на Dense слой и веса этого слоя в процессе обучения принимают значения, которые некоторым образом описывают фразу в слове.
Сравнительно небольшой текст преобразовался в гигантскую матрицу, где каждая фраза представлена вектором из 0 и одной 1. Длина вектора 10 млн. и количество таких векторов 10 000. Под такую матрицу расходовалось бы гигантское количество памяти. На практике для подачи текста на нейронную сеть используют подход Bag of Words [BOW].
При Bag Of Words последовательность слов в фразе убирается, поэтому фраза (на картинке Document1, Document2) представляется в виде вектора. Его длина равной размеру общего словаря всех анализируюмых текстов. В полученном векторе на позициях, соответствующих словам присутствующим в тексте стоят 1, а если слово в тексте не встретилось — 0.
В результате размерность матрицы, которая подается на нейронную сеть равна размер словаря х количество фраз (документов) или для нашего примера с отзывами 20000 х 10000.
Embedding
Ранее при обработке текстов, например, при рассмотрении рекуррентных сетей использовалась следующая преобраотка входной последовательности:
Рассмотрим как это выглядит в коде. Поскольку Dense слой — это матрица весов, сгенерируем такую рандомную матрицу:
hidden_size = 5 num_words = 10 dense_weights = np.random.normal(0, 1, (10, hidden_size))
array([[-1.32707206, 0.10119344, 1.79757198, 0.34618246, -1.54246334],
[-1.71555483, -0.41435209, 1.55291255, 0.45605782, -0.38036262],
[ 0.1468921 , -1.70855181, -0.11037113, -0.0230945 , 0.08609408],
[-2.00268987, 0.83066333, -0.11383054, -0.52439005, 1.92159762],
[ 0.83877495, -1.13184209, 0.60702018, -0.13582864, -0.4720022 ],
[-1.68540624, 0.4514039 , 0.141728 , -0.56166716, -0.08567821],
[-1.12092014, -0.89378575, -1.01579628, 0.28156886, 0.4657587 ],
[-0.97334435, -0.00635427, -0.06353585, -0.44005828, -1.48547527],
[-2.10256962, 0.80774305, -1.50179081, 0.63876112, 0.53071349],
[ 0.7122738 , 0.1074994 , 0.57170802, -0.47366115, -2.34293163]])На входе dense слоя (матрицы весов) подаются входные данные представленные в виде OHE. Например, для кодирования 10 слов используется следующая матрица OHE — по-сути, единичная квадратная матрица. У неё по диагонали стоят единицы:
I = np.eye(num_words)
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])Для обратного преобразования из матрицы OHE в порядковый номер слова в словаре (индекс) используется код:
np.argmax(I, axis = 1) array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
Соответственно, чтобы получить OHE соответствующий произвольному индексу, нужно взять из матрицы строку или столбец по нему:
def custom_OHE(index, num_classes): return np.eye(num_classes)[index]
token = 5 #Индекс нужного слова OHE_vector = custom_OHE(token, num_words) OHE_vector @ dense_weights array([-1.68540624, 0.4514039 , 0.141728 , -0.56166716, -0.08567821])
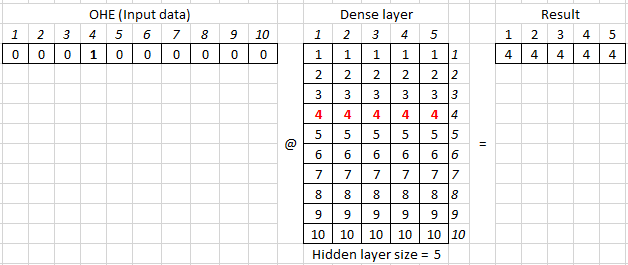
где @ — матричное умножение, аналог numpy.dot.
В параметрах dense слоя задается только размерность hidden size (в примере = 5). Вторую размерность (в данном случае = 10) dense слой берет из предыдущего слоя, выступающего для него в качестве входа.
Поскольку перемножение OHE на матрицу весов описывающих dense слой эквивалентно взятию из матрицы весов строки соответствующей индексу, то операция получения вектора (embedding) описыващего слово с выбранным индексом упрощается:
embedding = dense_weights token = 5 #Индекс нужного слова embedding [token] array([-1.68540624, 0.4514039 , 0.141728 , -0.56166716, -0.08567821])
По-сути, получаем словарь где слову с определенным индексом поставлен в соотвествие вектор с размерностью заданной для embedding-а.
model = Sequential() model.add(Embedding(num_words, embedding_size, input_length=max_len))
где
- num_words — количество слов в словаре,
- embedding_size — размерность embedding-а равна размеру скрытого слоя (hidden_size) dense слоя внутри embedding.
- max_len — размер входных данных. Например, тот-же max_len используется при выравнивании длины фраз x_train = pad_sequences(x_train_tokenized, maxlen=max_len).
Представление слов в виде embedding-ов — способ эффективно с точки зрения использования памяти представить слово в виде понятном для нейронной сети. При этом одинаковые слова имеют одинаковый вектор их представляющий.
Размер вектора задается исследователем и чаще всего варьируется от 8-ми мерного для небольших датасетов (текстов) до 1024 в случае больших текстовых баз. Embedding-и с высокой размерностью позволяют вычленять тонкие нюансы во взаимосвязях между словами, но требуют очень больших баз для обучения.
Физический смысл embedding
Помимо значительно большей эффективности использования оперативной памяти embedding-и обладают ещё одним полезным свойством.
Поскольку каждое слово из словаря раскладывается в виде многомерного вектора размерностью embedding_size, то можно предположить, что величина по каждой из осей что-то означает.
Важный момент, в embedding слову может соотвествовать только один вектор. Т.е. не смысловое значение для слова может быть только одно.
Например, был взят embedding_size = 2 и после тренировки embedding получен словарь двумерных векторов соответствующих слову. Их разместили на графике, отложив по оси X — одну координату вектора, а по Y — другую. После анализа слов получили, например, что ось X определяет определяет степень новизны слова, а по Y — насколько слово эмоционально положительное.
Для вектора работают математические операции сложения и вычитания. Кроме того можно вычислить угол между векторами для определения насколько они сонаправлены или ортогональны.
Но, что важно, вектора в многомерном пространстве можно сравнивать, используя косинусную меру.

Если угол между двумя векторами равен 0, то они сонаправлены и значение cos(0) будет равно 1, если ортогональны, то cos(pi/2) = 0, а если противоположно направлены, то cos(pi) = -1.
Косинусную меру можно использовать и как метрику и как loss. Как метрика она используется в исходном виде, как задан по формуле, поскольку метрика должна максимизироваться, т.е. стремится к 1.
В случае с loss его минимизируют, поэтому косинусную меру нужно вычесть из 1. В этом случае при максимальном сходстве векторов значение будет стремится к 0, когда вектора ортогональны, то к 1, а когда противоположно направлены = 2.
Если косинусная мера показывает меру смыслового сходства, то длина вектора дает степень окраски. Например, красивый, прекрасный, прекраснейший и пр. эпитеты ранжируются по степени.
Поскольку embedding может быть предобучен на больших корпусах (объемах) текстов с использованием специальных моделей, а затем выгружен в виде словаря, где слову ставится в соответствие вектор, то появляется возможность получать качественные предобученные embedding-и без необходимости их повторного обучения (веса слоя можно заморозить trainable = False).
from keras.layers import Embedding
embedding_layer = Embedding(len(word_index) + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)Тренировка embedding в зависимости от его размера занимает немало времени, поэтому такая оптимизация крайне полезна.
Word2Vec
Теперь проверим насколько теория о том, что полученные нейронкой вектора embedding-а действительно отражают что-то. Для этого воспользуемся моделью word2vec. При тренировке модели использовалось два подхода. Первый использовал метод continuous bag of words (CBOW), который по контексту пытается предсказать слово. Второй — использовать слово для предсказания контекста — skip-gram.

Word2Vec — это не предобученные эмбеддинги (файл с векторами), а подход к их формированию. Этот подход реализован, например, в библиотеке Gensim. Используя этот подход и большие корпуса текстов разного типа (например, новости) были созданы готовые файлы embedding-ов. Если посмотреть такой файл, то вначале идет слово, а затем набор чисел описывающих его векторное представление. Размерность embedding чаще всего от 100 до 1024.
Выше была дана формула косинусного расстояния. В Python она выглядит следующим образом:
def cos_distance(a , b): #метрика косинусного расстояния return a@b/((a@a)*(b@b))**0.5
Подгрузим embedding-и. Файл порядка 1,6 Гб, там только английские слова. При желании легко найти предобученные embedding-и для русского языка. В наименовании embedding указано 300 — это размерность векторов в embedding.
import gensim.downloader as api
wv = api.load('word2vec-google-news-300') #загружаем w2vШироко известный культовый пример для модели Word2Vec.

Посмотрим косинусное расстояние между
cos_distance(wv['king']-wv['man'], wv['queen']-wv['woman']) 0.7580350416366332
Действительно получаем высокое значение косинусного расстояния. Найдем меру сходства между walking и walked:
cos_distance(wv['walking'], wv['walked']) 0.6706871263449815
или то-же самое вычислим с помощью встроенной функции Word2Vec:
wv.similarity('walking', 'walked')
0.6706871В процессе обучения добавились того, чтобы если прибавление некоторого вектора к embedding слова «walking» приводил к появлению embedding слова «walked», то прибавление того-же вектора к слову swimming -> swam. Это называется «параллельный перенос«.
Найдем слово, которое выбивается из ряда слов:
print(wv.doesnt_match(['fire', 'water', 'land', 'man', 'sea', 'air'])) man
Или найдем слова, наиболее близкие по смыслу с точки зрения нейронной сети:
wv.similar_by_vector(wv['king'])
[('king', 0.9999999403953552),
('kings', 0.7138046026229858),
('queen', 0.6510956883430481),
('monarch', 0.6413194537162781),
('crown_prince', 0.6204219460487366),
('prince', 0.6159993410110474),
('sultan', 0.5864822864532471),
('ruler', 0.5797566771507263),
('princes', 0.5646551847457886),
('Prince_Paras', 0.543294370174408)]С русскими словами результат сходный:

Встраивание embedding в нейронную сеть
При работе с готовыми embedding-ами нужно их как-то подать в нейронную сеть. Используется два основных подхода. В первом исходные фразы конвертируются в массив векторов и уже этот массив подается на вход нейронной сети вместо комбинации OHE + Dense. В этом случае полученные вектора не будут тренироваться при тренировки нейронной сети. Они уже подготовлены и считается, что обучение произведено качественно, поскольку для этого использовались гигантские корпуса текстов и тренировка проводилась долго.
Сконвертируем слова в векторное представление:
sentence = 'I would like to have the flat'
x_sent = sentence.split(' ')
x_sent
['I', 'would', 'like', 'to', 'have', 'the', 'flat']И затем:
x_emb = []
for word in x_sent:
if word in wv.vocab:
x_emb.append(wv[word])
x_emb = np.array(x_emb)
x_emb.shape
(6, 300)Обращаю внимание на проверку if word in wv.vocab. Например, в примере частица to является стоп словом (stop-word) с минимальной для модели смысловой нагрузкой. Поэтому эта частица отсуствует в скаченном эмбеддинге.
Если запустить код без этой проверки, то он выпадет с ошибкой, что слово не найдено. Поэтому при трансформации я это слово пропускаю и поэтому в shape-е только 6, а не 7 векторов размерностью 300.
Второй подход — это встроить embedding в качестве слоя в архитектуру нейронной сети Keras. Для этого используется метод:
x = wv.get_keras_embedding(train_embeddings=True) #можно сразу получить embedding keras
Чтобы преобразовать слово в индекс в скаченном embedding используется следующий метод:
word_index = wv.vocab['king'].index #Преобразование слова -> индекс
print("Индекс:", word_index)
word = wv.index2word[word_index] #Обратное преобразование индекс -> слово
print("Слово:", word)
Индекс: 6147
Слово: kingВстраивание предоубченного embedding в нейронную сетью (Keras)
Есть два способа подать анализируемый текст на нейронку, используя предобученный embedding. В первом подходе входные данные адаптируются под слой embedding-а, а во втором — слой embedding-а подстраивается под входные индексы.
Первый способ состоит в конвертации входного текста с помощью словаря embedding-а и подаче подготовленного текста на слой с весами embedding в модели:
- Предложения в тексте разбить на последовательность слов c помощью Keras text_to_word_sequence. Словарь частотности не формируется. Если нужно ограничить словарь, то придется использовать Tokenizer.
- Преобразовать слова в индексы с помощью словаря предобученного embedding-а.
- Получить слой embedding-а с помощью get_keras_embedding().
- Встроить его первым слоем в модель. С весами слоя ничего не делаем!
- Подать на вход модели массив индексов полученных в п. 2.
Второй способ состоит в том, чтобы для индексов полученных токенизатором, например, Keras-а, поменять веса в матрице embedding-а, чтобы индекс определенного слова в embedding-е соответствовал индексу слова после токенизатора:
- Получить массив индексов с помощью Tokenizer. В этом случае словарь упорядочен по частоте появления слов в тексте, поэтому можно обрезать словарь с конца если нужно получить укороченный вариант.
- Получить предобученный embedding (обучить самому или скачать готовый).
- Адаптировать матрицу весов слоя embedding таким образом, чтобы индексу определенного слова после Tokenizer-а в слое embedding соответствовало то-же слово из словаря embedding-а.
Первый способ подготовки данных я рассмотрю в этой статье, а второй — в следующей.
Слой полученный get_keras_embedding() принимает на вход индексы из скаченного embedding-а. Для преобразования текст в последовательность индексов на которых тренировался скаченный embedding:
padding_index = 0 #Just for example
x_sent_arr = []
x_sent_arr.append('I would like to have the flat'.split(' '))
x_sent_arr.append('I would like to eat the apple'.split(' '))
x_train = []
for index, line in enumerate(x_sent_arr):
print(index, ':', line)
sentence = []
for word in line:
if word in wv.vocab:
sentence.append(wv.vocab[word].index)
else:
sentence.append(padding_index) # Do something. For example, leave it blank or replace with padding character's index.
x_train.append(sentence)
print(x_train)0 : ['I', 'would', 'like', 'to', 'have', 'the', 'flat'] 1 : ['I', 'would', 'like', 'to', 'eat', 'the', 'apple'] [[20, 47, 87, 0, 21, 11, 2532], [20, 47, 87, 0, 2785, 11, 13467]]
В некоторых случаях нужно подгрузить текст убрав лишние символы и пр. Если делать это Keras токенизатором, то для передачи индексов на embedding слой word2vec нужно слегка извратится, поскольку я не нашел нормального метода у Tokenizator для получения списка слов.
tokenizer = Tokenizer(filters='!–"—#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n\r«»', lower=True, split=' ', char_level=False)
tokenizer.fit_on_texts(x_sent_arr)
seq = tokenizer.texts_to_sequences(x_sent_arr)
text = tokenizer.sequences_to_texts(seq)
text = [line.split() for line in text]
print(text)
x_train = []
padding_index = 0
for line in text:
sentence = []
for word in line:
if word in wv.vocab:
sentence.append(wv.vocab[word].index)
else:
sentence.append(padding_index) # Do something. For example, leave it blank or replace with padding character's index.
x_train.append(sentence)
print(x_train) [['i', 'would', 'like', 'to', 'have', 'the', 'flat'], ['i', 'would', 'like', 'to', 'eat', 'the', 'apple']] [[4501, 47, 87, 0, 21, 11, 2532], [4501, 47, 87, 0, 2785, 11, 13467]]
Или без использования Tokenizer, взяв функцию text_to_word_sequence:
from keras.preprocessing.text import text_to_word_sequence
x_sent_arr = []
x_sent_arr.append('I would like to have the flat')
x_sent_arr.append('I would like to eat the apple')
text = [text_to_word_sequence(line, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ') for line in x_sent_arr]
print(text)
x_train = []
padding_index = 0
for line in text:
sentence = []
for word in line:
if word in wv.vocab:
sentence.append(wv.vocab[word].index)
else:
sentence.append(padding_index) # Do something. For example, leave it blank or replace with padding character's index.
x_train.append(sentence)
print(x_train)
[['i', 'would', 'like', 'to', 'have', 'the', 'flat'], ['i', 'would', 'like', 'to', 'eat', 'the', 'apple']]
[[4501, 47, 87, 0, 21, 11, 2532], [4501, 47, 87, 0, 2785, 11, 13467]]Если объем текста большой, а памяти GPU мало, то нужно использовать вариант с генератором. В этом случае данные будут подгружаться в нейронку batch-ами:
from keras.preprocessing.text import text_to_word_sequence
x_sent_arr = []
x_sent_arr.append('I would like to have the flat')
x_sent_arr.append('I would like to eat the apple')
def texts_to_sequences(texts, word2vec):
for text in texts:
tokens = text_to_word_sequence(text)
yield [word2vec.vocab[w].index for w in tokens if w in word2vec.vocab]
sequence = texts_to_sequences(x_sent_arr, wv)
for b in sequence:
print(b)
[4501, 47, 87, 21, 11, 2532]
[4501, 47, 87, 2785, 11, 13467]Продолжение следует.
Полезные ссылки
- TensorFlow — Word Embedding.
- Word2vec в картинках.
- Vector Semantics and Embeddings.
- RusVectōrēs: семантические модели для русского языка.
- Comparison of Top 6 Python NLP Libraries
- Using pre-trained word embeddings in a Keras model.
- GloVe: Global Vectors for Word Representation
- A Detailed Guide to understand the Word Embeddings and Embedding Layer in Keras.
- Using a Keras Embedding Layer to Handle Text Data.
- Чудесный мир Word Embeddings: какие они бывают и зачем нужны? — толковая статья.
- https://pathmind.com/wiki/word2vec