Для анализа финансовых данных необходимо их получить. Near realtime данные проще забирать с Yahoo Finance, нежели с Bloomberg. Видимо из-за новостной ориентации Bloomberg защита от web scraping значительно серьезнее. Если неосторожно забирать данные, то легко получить страницу с запросом captcha.
Ниже я приведу пример получения данных валюты и индексов с сайта Yahoo Finance на Python с использованием Chrome движка и Yahoo Finance API. Google Colab код здесь. Я забирал и парсил данные из JSON в html коде страниц, а не парсил страницы, хотя в коде есть небольшой пример как это делать с помощью библиотеки BeautifulSoup.
Код получения данных с Yahoo Finance
Для работы необходимы библиотеки Selenium, драйвер Chrome и библиотека для парсинга страниц BeautifulSoup.
!pip install selenium
!apt-get update # to update ubuntu to correctly run apt install
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
import sys
sys.path.insert(0,'/usr/lib/chromium-browser/chromedriver')
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
import pandas as pd
#import chromedriver_binary
from bs4 import BeautifulSoup
import re
import string
import time
from google.colab import files
from json import loadsПосле загрузки библиотек подгружается драйвер Chrome:
wd = webdriver.Chrome('chromedriver', chrome_options=chrome_options)Для получения данных по валютам используется простой код:
wd.get('https://finance.yahoo.com/currencies')
time.sleep(10)
currencies_html = wd.execute_script('return document.body.innerHTML;')
currencies_soup = BeautifulSoup(currencies_html,'lxml')
currencies_script = currencies_soup.find("script",text=re.compile("root.App.main")).text
data = loads(re.search("root.App.main\s+=\s+(\{.*\})", currencies_script).group(1))
#print(data)
info = []
stores = data["context"]["dispatcher"]["stores"]["StreamDataStore"]["quoteData"]
print("Number of currencies:", len(stores))
for store in stores:
name = data["context"]["dispatcher"]["stores"]["StreamDataStore"]["quoteData"][store]
nm = ""
value = ""
symbol = ""
if 'shortName' in name.keys():
nm = name["shortName"]
value = name["regularMarketPrice"]["raw"]
symbol = name["symbol"]
elif 'quoteSourceName' in name.keys():
nm = name["quoteSourceName"]
value = name["regularMarketPrice"]["raw"]
symbol = name["symbol"]
info.append([nm, symbol, value])
df = pd.DataFrame(data = info, columns=['Name', 'Symbol', 'Value'])
df['Value'] = df['Value'].map('{:,.2f}'.format)
dfПример результата:
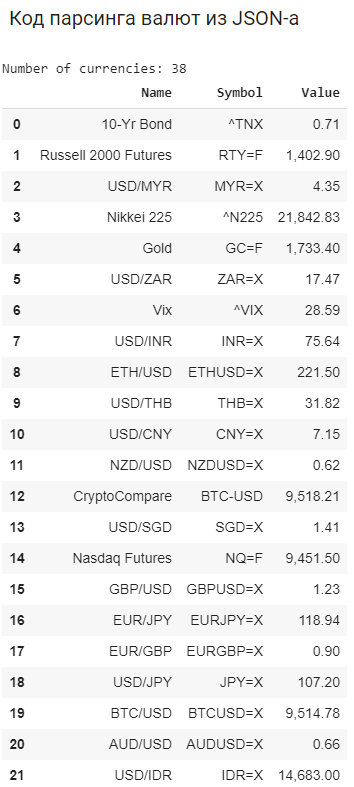
Парсинг HTML страниц Yahoo Finance
Хотя особого смысла парсить HTML страницы Yahoo Finance нет, поскольку в коде есть JSON файл, но для примера приведу небольшой кусок кода для получения названий индексов со страницы индексов.
symbols = ['\^GSPC', '\^DJI', '\^IXIC', '\^NYA', '\^XAX', '\^BUK100P', ]
for symbol in symbols:
indexes = [entry for entry in indexes_soup.find_all('tr', {'class': re.compile('data-row'+symbol)})] #'data-row^DJI Bgc($extraLightBlue):h BdT Bdc($tableBorderGray) Bdc($tableBorderBlue):h H(33px) Bgc($altRowColor)'})]
for index in indexes:
tds = index.find_all('td', {'class':'data-col0 Ta(start) Pstart(6px)'})
for td in tds:
a = td.find_all('a', {'class':'Fw(b)'})
print(a[0].attrs['data-symbol'], a[0].attrs['title'])Ну и незамысловатый результат работы кода:
^GSPC S&P 500 ^DJI Dow Jones Industrial Average ^IXIC NASDAQ Composite ^NYA NYSE COMPOSITE (DJ) ^XAX NYSE AMEX COMPOSITE INDEX ^BUK100P Cboe UK 100 Price Return
Получение данные через Yahoo API
Данные индексов можно получить через Yahoo API, используя библиотку yFinance https://github.com/ranaroussi/yfinance.
Загрузка библиотеки с подавлением вывода информации о прогрессе.
#@title Загрузка библиотеки yFinance https://github.com/ranaroussi/yfinance # to hide output of this cell %%capture !pip install yfinance import yfinance as yf
Получение финансовых данных. Наименование индексов можно посмотреть на скриншоте выше. Можно также воспользоваться скриптом https://pypi.org/project/Yahoo-ticker-downloader/.
#@title Код получения финансовых данных
ticker = yf.Ticker("GBPUSD=X")#("RUB=X")#("IDR=X")#(MSFT")
# get stock info
print(ticker.info)
# get historical market data
hist = ticker.history(period="5d")
#@title Код для вывода
#hist.dtypes
hist['Open'] = hist['Open'].astype(float)
hist['Close'] = hist['Close'].astype(float)
hist['High'] = hist['High'].astype(float)
hist['Low'] = hist['Low'].astype(float)
hist['Open'] = hist['Open'].map('{:,.2f}'.format)
hist['Close'] = hist['Close'].map('{:,.2f}'.format)
hist['High'] = hist['High'].map('{:,.2f}'.format)
hist['Low'] = hist['Low'].map('{:,.2f}'.format)
hist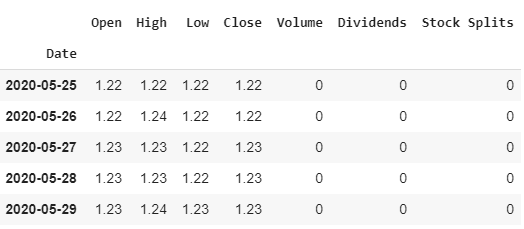
Альтернативные источники финансовой информации
Помимо Yahoo Finance есть другие источники финансовой информации. Исторические данные по некоторым курсам и индексам с интервалом в 1 минуту удобно взять https://www.histdata.com/category/quotes-update/.
Полезные ссылки:
- Google запрос для поиска информации.
- https://towardsdatascience.com/web-scraping-yahoo-finance-477fe3daa852
- https://hackernoon.com/scraping-yahoo-finance-data-using-python-ayu3zyl
- https://medium.com/c%C3%B3digo-ecuador/how-to-scrape-yahoo-stock-price-history-with-python-b3612a64bdc6
- http://www.compjour.org/warmups/govt-text-releases/intro-to-bs4-lxml-parsing-wh-press-briefings/ — работа с BeutifulSoup
- Для просмотра JSON удобный инструмент.