В предыдущей статье я подробно разобрал учебный пример использования seq2seq модели для разработки чатбота. В этой реализации seq2seq используется преобразование обучающей последовательности подаваемой на выход декодера модели в One Hot Encoding. Поскольку на выходе получается гигантская разреженная матрица, то она быстро потребляет всю доступную память и «роняет» Colab. Есть два способа решения проблемы: в качестве loss в декодере использовать sparse_categorical_crossentropy, либо написать генератор, который будет конвертировать в OHE только батч, подаваемый на модель, а не весь текст.
В текущем примере я рассмотрю вариант с использованием sparse_categorical_crossentropy. Немного напомню в чем суть модели seq2seq.
Encoder (кодировщик):
- На модель подается последовательность, например, слов в предложении (вопрос, предложение для перевода) — seq.
- Предложения токенизируется для перевода слов в предложении в последовательность индексов из построенного токенизатором словаря.
- Поскольку длина предложений разная, находится максимальное по длине предложение и с помощью pad_sequences все предложения выравниваются по длине добавлением 0-ей. В модели используется свойство mask_zero = True, чтобы сказать сети игнорировать пропуски.
- Слова в последовательности преобразуются в пространство векторов (embedding) в самой модели или при использовании предобученных embedding.
- У рекуррентной сети, используемой в модели (LSTM или GRU) используется свойство return_state = True, чтобы на выходе получить сжатое представление поданного слова (thought vector) в виде двух векторов состояний h и c.
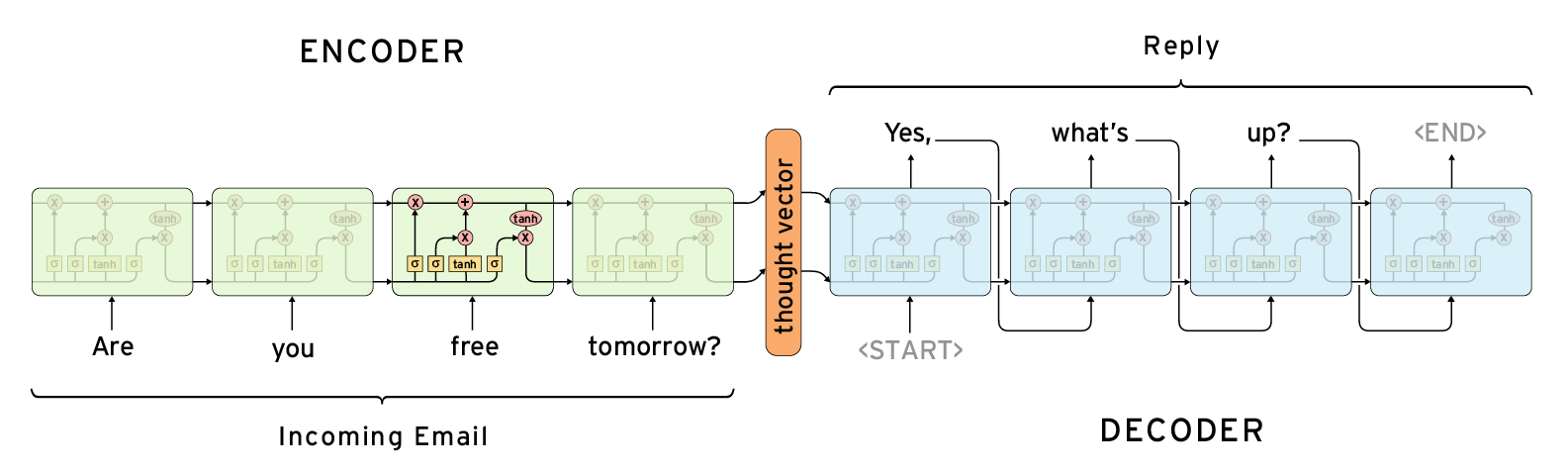
На выходе encoder-а входная последовательность индексов преобразуется в вектор состояний или «thought vector». Этот вектор подается на декодер.
Декодер на выходе должен преобразовать последовательность на входе encoder в последовательность выходе декодера (ответ) неопределенной длины. Поэтому модель называется — seq2seq. В общем случае, длина последовательности на выходе декодера не равна длине последовательности на входе encoder. Например, на входе слово на русском, а на выходе на китайском. Очевидно, что длины предложений будут совпадать далеко не всегда.
При этом на этапе обучения длина выходной последовательности известна, поэтому обучать можно обычным способом, выровняв длины предложений добавлением 0-ей.
Decoder (декодер):
- Принимает на вход состояние («thought vector») с encoder-а через параметр initial_state рекуррентной сети.
- Последовательность в которую происходит преобразование дополняется специальными тегами:
- Начало последовательности подаваемой на вход декодера в начале дополняется тегом <start> (может быть использован любой тег, например, <BOS>, гарантированно не встречающийся в тексте).
- Конец последовательности подаваемой на выход декодера в конце дополняется тегом <end> (может быть использован любой тег, например, <EOS>, гарантированно не встречающийся в тексте).
- Последовательность дополненная тегом <start> преобразуется в пространство векторов с помощью embedding и подается на вход декодера.
- Последовательность индексов дополненная индексом тега <end> подается на выход декодера (dense слой) без преобразования в embedding. Модель обучается категоризации, т.е. выдавать индекс слова из словаря с некоторой вероятностью. Соответственно, в качестве активационной функции используется activation=’softmax’. Подавать на выход индексы вместо OHE можно, поскольку используется loss=’sparse_categorical_crossentropy’.
- Encoder и decoder обучаются в общей модели.
Teacher forcing
Выходы ячеек рекуррентной сети декодера можно подавать на вход следующей ячейки напрямую (free running), что будет множить ошибку. В данном случае лучше использовать правильные значения индексов, которые подаются на следующую ячейку.

См. https://www.youtube.com/watch?v=I7UFPBDLDIk
В случае с подачей заведомо правильной последовательности реализуется механизм «teacher forcing». «Учитель» (обучающая последовательность на выходе) на каждой ячейке «поправляет» результат сформированный предыдущей ячейкой рекуррентной сети. Фактически каждая ячейка получает заведомо правильную последовательность на входе, не используя, возможно, неправильно предсказанную предыдущей ячейкой.
Если взять пример из жизни, то «teacher forcing» напоминает «парное программирование» или наставничество, когда при написании кода рядом с разработчиком сидит другой девелопер, смотрит код, который пишет первый разработчик и сразу поправляет его, если допущена ошибка. Такой подход эффективнее, нежели вариант, когда готовый код отдается тестировщику. Тот начинает тестировать и дает разработчику обратную связь по которой тому надо найти ошибки в коде. Чем раньше выявляется ошибка, тем дешевле её исправить.
Пример реализации модели без использования механизма «teacher forcing» можно посмотреть здесь. Цикл обработки выходной последовательности реализован при построении модели. Выходные данные на вход декодера не подаются. Только на выход.
Код encoder и decoder в модели seq2seq
Данные для подачи на вход модели:
- Каждый вопрос подгружаются с список. Дополнительные теги в начало вопроса не добавляются.
- Каждый ответ разбивается на два списка:
- В ответ подаваемый на вход декодера добавляется тег <start>.
- В ответ подаваемый на выход декодера добавляется тег <end>.
- Вопросы и ответы объединяются и обрабатываются токенизатором.
- Находится максимальная длина вопроса maxLenQuestions.
- Используя pad_sequences длины вопросов выравниваются, добивая 0-мя до максимальной длины вопроса.
- Находится максимальная длина ответа maxLenAnswers. Поскольку к каждому ответу добавляется только один тег, то длина будет одинаковой и для подаваемой на вход декодера и на выход.
- Используя pad_sequences длины ответов выравниваются, добивая 0-мя до максимальной длины вопроса.
- После обработки получается два массива для подачи на вход декодера и его выход.
#@title Импорт библиотек #from google.colab import files # модуль для загрузки файлов в colab import numpy as np #библиотека для работы с массивами данных from tensorflow.keras.models import Model, load_model, Sequential # из кераса подгружаем абстрактный класс базовой модели, метод загрузки предобученной модели from tensorflow.keras.layers import Dense, Embedding, LSTM, GRU, Input, TimeDistributed, RepeatVector # из кераса загружаем необходимые слои для нейросети from tensorflow.keras.optimizers import RMSprop, Nadam # из кераса загружаем выбранный оптимизатор from tensorflow.keras.preprocessing.sequence import pad_sequences # загружаем метод ограничения последовательности заданной длиной from tensorflow.keras.preprocessing.text import Tokenizer # загружаем токенизатор кераса для обработки текста from tensorflow.keras import utils # загружаем утилиты кераса для one hot кодировки from tensorflow.keras.utils import plot_model # удобный график для визуализации архитектуры модели import os import re import tensorflow.keras as keras import sys import time from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
Нет смысла публиковать код парсера, поскольку он зависит от dataset-а. Вот пример парсинга некоторого диалога для обучения.
questions, answers_in, answers_out = parseText('dialogs_8000.txt')
Вопрос: Как дела
На вход декодера: <START> Все хорошо
На выход декодера: Все хорошо <END>
Вопрос: Где ты живешь
На вход декодера: <START> Я живу во Вселенной
На выход декодера: Я живу во Вселенной <END>
Вопрос: Где я живу
На вход декодера: <START> Ты живешь на планете Земля
На выход декодера: Ты живешь на планете Земля <END> Далее подключаем Keras-овский токенизатор
#@title Подключаем керасовский токенизатор и собираем словарь индексов { display-mode: "form" }
vocabularySize = None #10000 #30000
tokenizer = Tokenizer(num_words = vocabularySize, filters = '!"#$%&()*+,-./:;=?@[\\]^_`{|}~\t\n', oov_token='<unk>') #num_words=vocabularySize, filters='!–"—#$%&()*+,-./:;=?@[\\]^_`{|}~\t\n\r«»'
tokenizer.fit_on_texts(questions)
tokenizer.fit_on_texts(answers_in)
tokenizer.fit_on_texts(answers_out)
#tokenizer.fit_on_texts(questions + answers)
vocabularyItems = list(tokenizer.word_index.items()) # список с cодержимым словаря
if (vocabularySize == None):
vocabularySize = len(vocabularyItems)+1 # размер словаря
else:
if len(vocabularyItems)+1 < vocabularySize:
vocabularySize = len(vocabularyItems)+1
print( 'Фрагмент словаря : {}'.format(vocabularyItems[:100]))
print( 'Размер словаря : {}'.format(vocabularySize))Фрагмент словаря : [('<unk>', 1), ('<start>', 2), ('<end>', 3), ('в', 4), ('и', 5), ('не', 6), ('на', 7), ('что', 8), ('я', 9)....]
Размер словаря : 47384Подготавливаем данные для обработки:
#@title Подготавливаем данные для нейронной сети (вопросы или ответы) { display-mode: "form" }
def prepareDataForNN(phrases, tokenizer, isQuestion = True):
tokenizedPhrases = tokenizer.texts_to_sequences(phrases)
maxLenPhrases = max([len(x) for x in tokenizedPhrases]) #берем длину самой длинной фразы
paddedPhrases = pad_sequences(tokenizedPhrases, maxlen = maxLenPhrases, padding='post', truncating='post')
phraseType = "вопрос"
if not isQuestion:
phraseType = "ответ"
print('Пример оригинального ' + phraseType + 'а на вход : {}'.format(phrases[100]))
print('Пример кодированного ' + phraseType + 'а на вход : {}'.format(paddedPhrases[100]))
print('Размеры закодированного массива ' + phraseType + 'ов на вход : {}'.format(paddedPhrases.shape))
print('Установленная длина ' + phraseType + 'ов на вход : {}'.format(maxLenPhrases))
return paddedPhrases, maxLenPhrasesПодготавливаем вопросы для подачи данных на encoder:
#@title Устанавливаем закодированные входные данные(вопросы) { display-mode: "form" }
encoderForInput, maxLenQuestions = prepareDataForNN(questions, tokenizer)Пример оригинального вопроса на вход : Что такое палеоэндемик Пример кодированного вопроса на вход : [ 8 39 16480 0 ... 0] Размеры закодированного массива вопросов на вход : (18024, 84) Установленная длина вопросов на вход : 84
Подготавливаем данные ответов для подачи на декодер:
#@title Устанавливаем раскодированные входные данные (ответы) { display-mode: "form" }
decoderForInput, maxLenAnswers = prepareDataForNN(answers_in, tokenizer, False)
print()
decoderForOutput, maxLenAnswers = prepareDataForNN(answers_out, tokenizer, False)Пример оригинального ответа на вход : <START> Реликтовый исчезающий вид Пример кодированного ответа на вход : [ 2 8485 8486 273 0 ... 0] Размеры закодированного массива ответов на вход : (18024, 254) Установленная длина ответов на вход : 254 Пример оригинального ответа на вход : Реликтовый исчезающий вид <END> Пример кодированного ответа на вход : [8485 8486 273 3 0 ... 0] Размеры закодированного массива ответов на вход : (18024, 254) Установленная длина ответов на вход : 254
Если импортируется старая версия Keras, то на dense слой не получится подать двухмерный вектор после pad_sequence, поскольку он ожидает 3-х мерный вектор. В этом случае нужно будет сделать reshape:
#Изменяем размерность для sparse_categorical_crossentropy. Вариант 1. #Нужно, если используютсяслои из keras.layer, а не tensorflow.keras decoderForOutput_4sparse = decoderForOutput.reshape(decoderForOutput.shape[0], decoderForOutput.shape[1], 1) decoderForOutput_4sparse.shape #или так #Изменяем размерность для sparse_categorical_crossentropy. Вариант 2. decoderForOutput_4sparse = np.expand_dims(decoderForOutput, -1) decoderForOutput_4sparse.shape (18024, 254, 1)
Поскольку рекуррентные слои обучаются очень долго, а Colab может периодически вылетать, имеет смысл сохранять веса сети на ftp:
#@title Класс callback-а для сохранения весов нейронной сети { display-mode: "form" }
class MyCallback(keras.callbacks.Callback):
def __init__(self, filename):
super().__init__()
if (filename == ''):
filename = "best_weights_chatbot_150_epochs.h5"
self.best_criterion = sys.float_info.max
self.counter = 0
self.interval = 5 #Интервал для сохранения
self.best_weights_filename = filename
print(self.best_weights_filename)
def on_epoch_begin(self, epoch, logs={}):
self.epoch_time_start = time.time()
def on_epoch_end(self, epoch, logs=None):
#'loss', 'val_loss', 'val_mean_squared_error', 'mean_squared_error'
criterion = 'loss'
if (logs[criterion] < self.best_criterion):
print("\r\nНайдено лучшее значение " + criterion + ". Было", self.best_criterion, "Стало:", logs[criterion], "Сохраняю файл весов. Итерация:", self.counter, "\r\n")
self.model.save_weights(self.best_weights_filename) #"best_weights.h5"
if ((self.counter % self.interval) == 0):
print("Сохраняю файл весов на ftp.")
!curl -ss -T $self.best_weights_filename ftp://login:password@site.ru
self.best_criterion = logs[criterion] #Сохраняем значение лучшего результата
self.counter += 1
#early_stopping = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2, verbose=1, patience=3, min_lr=1e-12)
earlyStopper = EarlyStopping(monitor='val_loss', patience=5)Восстановление весов модели:
best_weights_filename = 'best_weights_chatbot_150_epochs.h5'
def loadSavedWeights(model, filename, kill_local_file = False):
url = "http://www.site.ru/uploads/Colab/"
fullpath = url + filename
if (kill_local_file):
!rm $filename
loaded = loadfiles(filename, fullpath, user = "login", password = "password", unzip = False)
model.load_weights(filename)Код модели seq2seq на Keras
Код для кодировщика:
hidden_size = 196
embedding_size = 196
#@title Первый входной слой, encoder { display-mode: "form" }
#encoderInputs = Input(shape=(maxLenQuestions , ), name = "EncoderForInput")
encoderInputs = Input(shape=(None, ), name = "EncoderForInput")
encoderEmbedding = Embedding(vocabularySize, embedding_size, mask_zero = True, name = "Encoder_Embedding") (encoderInputs) #
_, state_h , state_c = LSTM(hidden_size, return_state = True, name = "Encoder_LSTM")(encoderEmbedding)
encoderStates = [state_h, state_c]
encModel = Model(encoderInputs, encoderStates)Код для decoder:
#@title Второй входной слой, decoder { display-mode: "form" }
#decoderInputs = Input(shape=(maxLenAnswers, ), name = "DecoderForInput")
decoderInputs = Input(shape=(None, ), name = "DecoderForInput")
decoderEmbedding = Embedding(vocabularySize, embedding_size, name = "Decoder_Embedding") (decoderInputs) #mask_zero=True - очень просаживает обучение
decoderLSTM = LSTM(hidden_size, return_state=True, return_sequences=True, name = "Decoder_LSTM")
decoderOutputs , _ , _ = decoderLSTM(decoderEmbedding, initial_state = encoderStates)
decoderDense = Dense(vocabularySize, activation='softmax', name = "Decoder_Output")
decoderOutput = decoderDense(decoderOutputs)Собираем тренировочную модель нейросети seq2seq:
#@title Собираем тренировочную модель нейросети { display-mode: "form" }
model_LSTM = Model([encoderInputs, decoderInputs], decoderOutput)
#RMSprop()
model_LSTM.compile(optimizer=Nadam(lr=0.001), loss='sparse_categorical_crossentropy', metrics=['sparse_categorical_accuracy'])
print(model_LSTM.summary())
plot_model(model_LSTM, to_file='model.png', show_shapes=True)Если вместо ‘sparse_categorical_accuracy’ указать просто ‘accuracy’, то Keras все равно по loss определит, что в качестве метрики нужно использовать ‘sparse_categorical_accuracy’.
______________________________________________________________________________
Layer (type) Output Shape Param # Connected to
================================================================
EncoderForInput (InputLayer) [(None, None)] 0
______________________________________________________________________________
DecoderForInput (InputLayer) [(None, None)] 0
______________________________________________________________________________
Encoder_Embedding (Embedding) (None, None, 196) 9287264 EncoderForInput[0][0]
______________________________________________________________________________
Decoder_Embedding (Embedding) (None, None, 196) 9287264 DecoderForInput[0][0]
______________________________________________________________________________
Encoder_LSTM (LSTM) [(None, 196), (None, 308112 Encoder_Embedding[0][0]
______________________________________________________________________________
Decoder_LSTM (LSTM) [(None, None, 196), 308112 Decoder_Embedding[0][0]
Encoder_LSTM[0][1]
Encoder_LSTM[0][2]
______________________________________________________________________________
Decoder_Output (Dense) (None, None, 47384) 9334648 Decoder_LSTM[0][0]
================================================================
Total params: 28,525,400
Trainable params: 28,525,400
Non-trainable params: 0
______________________________________________________________________________Модель с 28, 5 млн. параметрами достаточно большая и может приводить к неизвестной ошибке, которая устраняется упрощением модели:

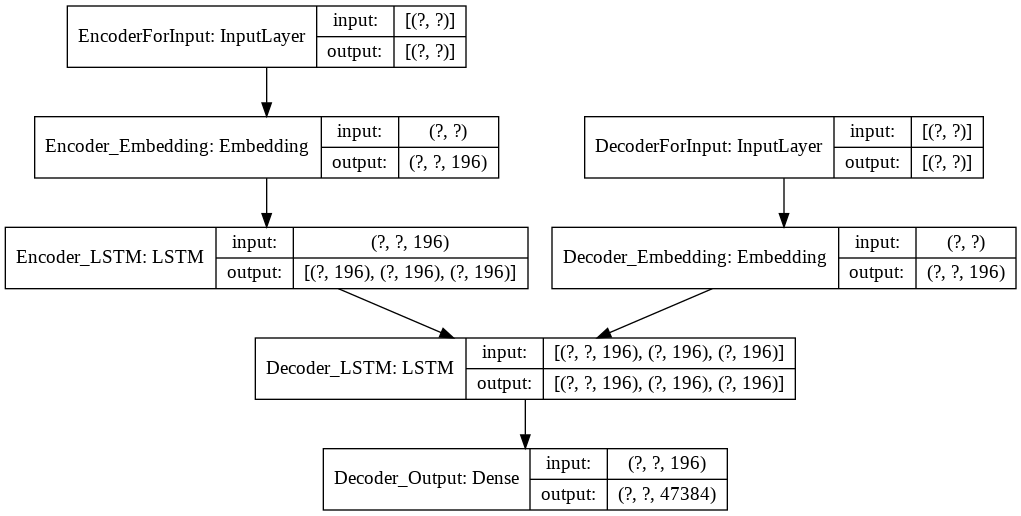
Запускаем модель seq2seq на тренировку:
best_weights_filename = "best_weights_LSTM_chatbot_epochs_with_mask_zero_.h5"
#loadSavedWeights(model_LSTM, best_weights_filename)
model_LSTM.fit([encoderForInput , decoderForInput], decoderForOutput, batch_size=32, epochs=50, validation_split=0.2, callbacks=[MyCallback("best_weights_LSTM_chatbot_epochs_with_mask_zero.h5"), reduce_lr, earlyStopper]) Обращаю внимание на то, что на выходе dense слоя 47384 возможных категории определяемых размером словаря. Какие-то слова будут с более высоким приоритетом и argmax сможет отобрать их.
Inference для seq2seq
Два варианта реализации inference. Классический вариант, который везде используется:
#@title Создаем рабочую модель для вывода ответов на запросы пользователя { display-mode: "form" }
def makeInferenceModels(encoderInputs, decoderInputs, encoderStates, decoderEmbedding, hidden_layer_size = 128):
encoderModel = Model(encoderInputs, encoderStates)
decoderStateInput_h = Input(shape=(hidden_layer_size ,), name = 'decoderStateInput_h')
decoderStateInput_c = Input(shape=(hidden_layer_size ,), name = 'decoderStateInput_c')
decoderStatesInputs = [decoderStateInput_h, decoderStateInput_c]
decoderOutputs, state_h, state_c = decoderLSTM(decoderEmbedding, initial_state=decoderStatesInputs)
decoderStates = [state_h, state_c]
decoderOutputs = decoderDense(decoderOutputs)
decoderModel = Model([decoderInputs] + decoderStatesInputs, [decoderOutputs] + decoderStates)
plot_model(decoderModel, to_file='decoderModel.png', show_shapes=True)
return encoderModel, decoderModelДругой вариант, который я нигде не встречал. Им поделился преподаватель «Университета искусственного интеллекта» Константин Слепов.
#@title Создаем рабочую модель для вывода ответов на запросы пользователя { display-mode: "form" }
def makeInferenceModels(model, num_words, hidden_size = 128):
decoder_input = Input((None,))
decoderStateInput_h = Input((hidden_size,))
decoderStateInput_c = Input((hidden_size,))
decoderStatesInputs = [decoderStateInput_h, decoderStateInput_c]
#Копируем веса слоев декодера
emb_weights = model.get_layer(name='Decoder_Embedding').get_weights()
lstm_weights = model.get_layer(name='Decoder_LSTM').get_weights()
dense_weights = model.get_layer(name='Decoder_Output').get_weights()
decoderEmbedding = Embedding(num_words, hidden_size, weights = emb_weights, name='Decoder_Embedding')(decoder_input)
#mask_zero = True,
lstm, h, c = LSTM(hidden_size, return_state=True, weights = lstm_weights, name='Decoder_LSTM')(decoderEmbedding, initial_state = decoderStatesInputs)
output = Dense(num_words, activation='softmax', weights = dense_weights, name='Decoder_Output')(lstm)
decoderModel = Model([decoder_input]+decoderStatesInputs, [output, h, c])
plot_model(decoderModel, to_file='decoderModel.png', show_shapes=True)
return decoderModel При запуске рабочей модели в работу на её вход подается состояния c,h с выхода encoder и они подаются на обученный в составе объединенной модели decoder. Чтобы перенести вусщвук из учебной модели в рабочую достаточно скопировать веса из учебной модели в рабочую.
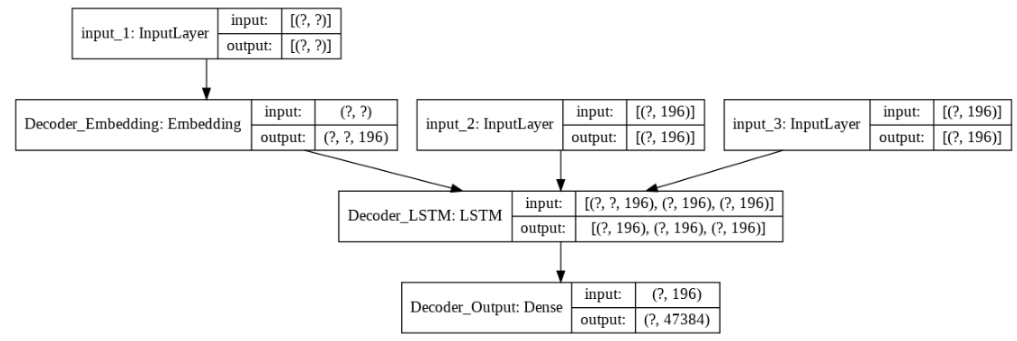
Строим inference модель:
from IPython.display import SVG
from keras.utils import model_to_dot
import matplotlib.pyplot as plt
import matplotlib.image as img
#encModel , decModel = makeInferenceModels(encoderInputs, decoderInputs, encoderStates, decoderEmbedding, hidden_size) # запускаем функцию для построения модели кодера и декодера
decModel = makeInferenceModels(model_LSTM, vocabularySize, hidden_size)
# reading png image file
im = img.imread('decoderModel.png')
# show image
plt.figure(figsize=(20,10))
plt.axis('off')
plt.imshow(im)Чтобы запустить модель нужно преобразовать исходный вопрос пользователя в последовательность индексов из словаря токенизатора.
#@title Функция преобразующая вопрос пользователя в последовательность индексов { display-mode: "form" }
def strToTokens(sentence: str): # функция принимает строку на вход (предложение с вопросом)
sentence = sentence
words = sentence.lower().split()
tokensList = list()
for word in words:
tokensList.append(tokenizer.word_index[word])
return pad_sequences([tokensList], maxlen=maxLenQuestions , padding='post')Запускаем обученную модель чатбота.
- Для получения h и c последовательность индексов вопроса подается на вход ранее обученного encoder-а.
- Далее запускается цикл формирования ответа.
- Для инициализации decoder-а на его вход подается индекс стартового тега и состояние encoder-а.
decOutputs, h, c = decModel.predict([emptyTargetSeq] + statesValues) - На выходе inference модели на dense слое нужно найти argmax индекс слова с максимальной вероятностью.
- Полученный индекс слова преобразуется sequences_to_texts в слово. Это слово добавляется к предложению.
- Найденный индекс слова подается на ячейку рекуррентного слоя в качестве нового слова. Также подаются полученные состояния h и c.
- На очередной интерации модель inference обрабатывает полученное состояние и индекс предсказанного слова и делает новый прогноз.
- Предложение считается сформированным если inference модель сформировала на выходе тег <end>, либо длина ответа превысила максимальную длину ответа maxLenAnswers.
#@title Устанавливаем окончательные настройки и запускаем модель { display-mode: "form" }
for _ in range(6): # задаем количество вопросов, и на каждой итерации в этом диапазоне:
statesValues = encModel.predict(strToTokens(input( 'Задайте вопрос : ' )))
emptyTargetSeq = np.zeros((1, 1))
emptyTargetSeq[0, 0] = tokenizer.word_index['<start>'] # положим в пустую последовательность начальное слово 'start' в виде индекса
stopCondition = False
decodedTranslation = ''
while not stopCondition:
decOutputs, h, c = decModel.predict([emptyTargetSeq] + statesValues)
sampledWordIndex = np.argmax(decOutputs, axis = -1) #находим индекс слова
sampledWord = tokenizer.sequences_to_texts([sampledWordIndex])[0] #конвертим в слово
if sampledWord == '<end>' or len(decodedTranslation.split()) > maxLenAnswers:
stopCondition = True #
else:
decodedTranslation += sampledWord + ' ' #чтобы тег <end> не попал в ответ
emptyTargetSeq[0, 0] = sampledWordIndex
statesValues = [h, c]
print(decodedTranslation)Здесь реализован простой «greedy search», когда выбирается одно слово с наибольшей вероятностью. Более сложный вариант реализации — «beam search» в котором выбирается несколько слов с наибольшей вероятностью и затем используется алгоритм Витерби для выбора наилучшего слова.
Библиотека для seq2seq на Keras
Поскольку seq2seq модель широко используется, есть готовые реализации модели на Keras. Например, эта seq2seq библиотека.
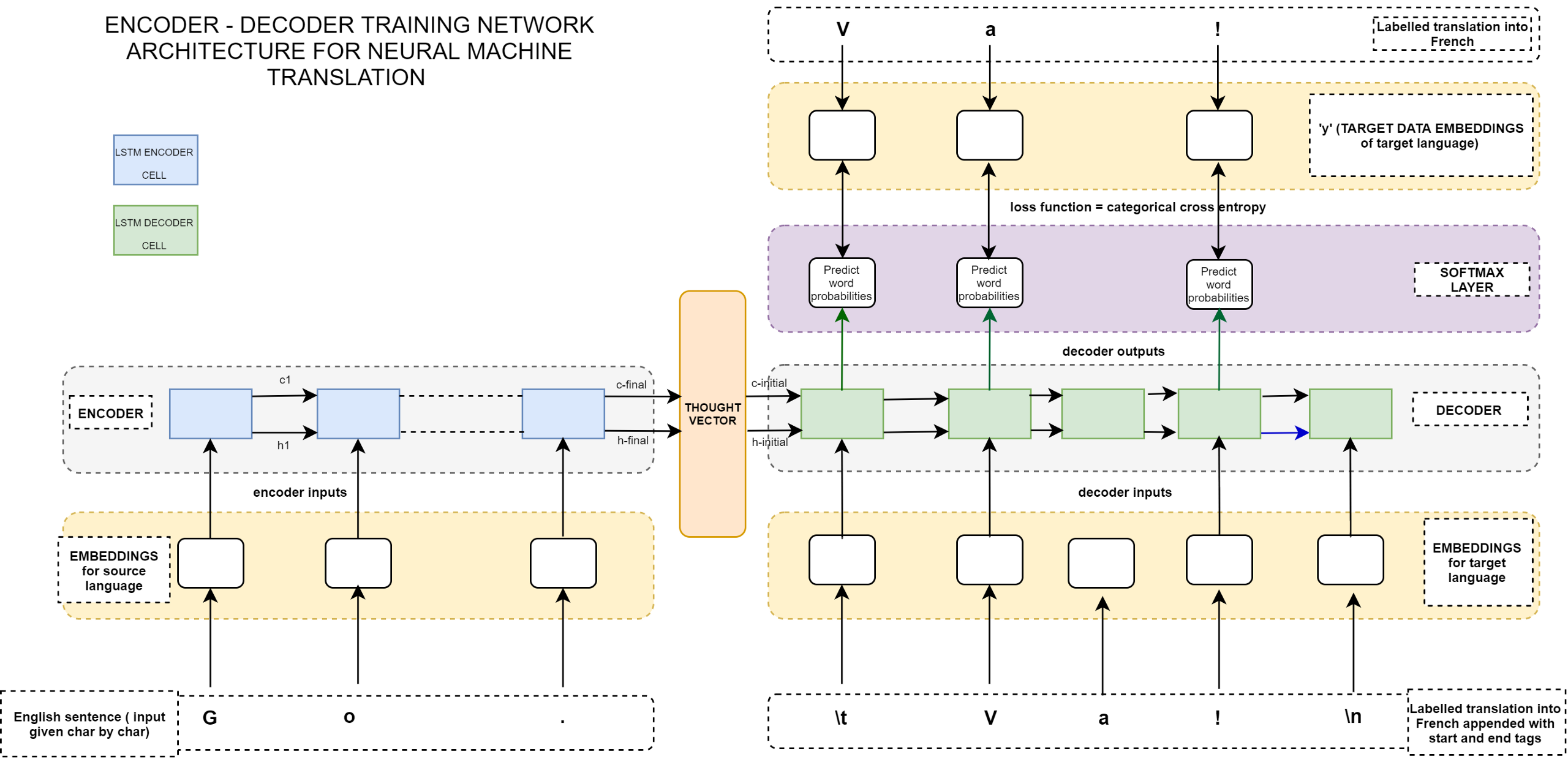
Визуализация модели для посимвольного перевода
Картинка взята отсюда. Странно, что на рисунке данные на выход декодера подаются без закрывающего тега/символа ‘\n’. Окрывающий и закрывающий теги есть только в данных на входе декодера.
Полезные ссылки
- A ten-minute introduction to sequence-to-sequence learning in Keras
- NLP | Sequence to Sequence Networks| Part 1| Processing text data
- NLP | Sequence to Sequence Networks| Part 2|Seq2seq Model (EncoderDecoder Model)
- Peeking into the neural network architecture used for Google’s Neural Machine Translation
- How to Develop a Seq2Seq Model for Neural Machine Translation in Keras
- Encoder-Decoder Models for Text Summarization in Keras
- How to Develop an Encoder-Decoder Model for Sequence-to-Sequence Prediction in Keras
- How to Implement a Beam Search Decoder for Natural Language Processing.
- https://github.com/mmehdig/lm_beam_search/blob/master/beam_search.py
- An intuitive explanation of Beam Search