Эта статья — конспект лекции Константина Слепова, читаемой в «Университете искуственного интеллекта» в курсе «Углубленный курс по текстам (Natural Language Processing)».
Предположим есть задача последовательного предсказания букв некоторой последовательности. Например, мы хотим получить модель в которой по трем буквам происходит предсказание четвертой.
Подавать три символа на вход dense слоя неправильно, поскольку теряется информация о последовательности слов в слове.
Предположим, нам нужно собрать последовательность букв в слово «ПРИВЕТ».
- ПРИ -> предсказываем следующую букву «В», смещаемся на одно слово
- РИВ -> предсказываем следующую букву «Е», смещаемся на одно слово
- ИВЕ -> предсказываем следующую букву «Т».
Если бы такая задача решалась на dense слоях, то модель нейронной сети выглядела бы следущим образом.
Нейронка для предсказания следующего символа в слове
Каждый символ русского алфавита для нейронной сети кодируется в виде one hot encoding (OHE). Размерность вектора 33 буквы русского алфавита + символ пробела для формирования предложений и символ переноса строки = 35. Это разреженная (sparse) матрица где в строке все нули и одна единица в позиции соотвествующей номеру символа.
Можно подавать номера символов без кодирования в OHE, но тогда нужно использовать loss = ‘sparse_categorical_crossentropy’.
Итак, в простейшем случае модель сети для предсказания третьей буквы по 3-м предыдущим на dense слоях будет выглядеть так:

С каждой буквой производится операция преобразования в веса dense слоя, а затем конкатенация с выходом dense слоя в котором представлены объединенные слова. Так циклически по всем буквам. На выходе dense слой который предсказывает 4-й символ по 3-м предыдущим.
Код на dense слоях
Импортируем нужные библиотеки:
import numpy as np from tensorflow.keras.layers import Dense, SimpleRNN, Concatenate, Input, concatenate, LSTM, Embedding from tensorflow.keras.models import Model, Sequential from tensorflow.keras.optimizers import Adam from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.utils import to_categorical, plot_model from tensorflow.keras.preprocessing.sequence import pad_sequences import io import re #from google.colab import drive import matplotlib.pyplot as plt %matplotlib inline
Для начала уберем из исходного текста лишние символы.
with io.open('Text.txt', 'r', encoding='utf-8') as f:
text = f.read()
text = text.replace('\ufeff', '') #убираем первый невидимый символ
text = re.sub(r'[^А-я \n]', '', text) #заменяем все символы кроме кириллицы на пустые символыЗатем обрабатываем текст как последовательность символов:
#парсим текст, как последовательность символов
num_characters = 34 #33 буквы + пробел
tokenizer = Tokenizer(num_words=num_characters, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', char_level=True) #токенизируем на уровне символов
tokenizer.fit_on_texts(text) #формируем токены на основе частотности в нашем тексте
tokenizer.word_indexТокенизация производится не на уровн слов, а на уровне символов: char_level=True. На выходе токенизатор выдает буквы с соответствующим кодом символа.
{'\n': 24,
' ': 1,
'а': 4,
'б': 22,
'в': 10,
'г': 20,
'д': 14,
'е': 3,
'ж': 26,
'з': 19,
'и': 6,
'й': 25,
'к': 12,
'л': 9,
'м': 13,
'н': 5,
'о': 2,
'п': 16,
'р': 11,
'с': 8,
'т': 7,
'у': 15,
'ф': 33,
'х': 27,
'ц': 31,
'ч': 23,
'ш': 28,
'щ': 32,
'ъ': 34,
'ы': 18,
'ь': 21,
'э': 30,
'ю': 29,
'я': 17}Токенизатором преобразуем последовательность букв в токены:
tokenized_text = tokenizer.texts_to_sequences('привет') #преобразуем последовательности букв в последовательности токенов
tokenized_text
[[16], [11], [6], [10], [3], [7]]И затем каждый токен преобразуем в послеовательность векторов OHE:
data = tokenizer.texts_to_matrix('привет') #последовательности токенов в OHEНа выходе будет матрица с количеством строй = 6 по количеству символов в слове и каждая строка представлена вектором с длиной 35 (OHE).
Для проверки, что обратное преобразование токенизированного слова происходит корректно:
word_tokens = tokenizer.texts_to_matrix('привет').argmax(axis=1)
word_tokens
array([16, 11, 6, 10, 3, 7])Argmax восстанавливает из OHE вектор из токенов описыващих символы. Пробегаясь с цикле по вектору и подставляя полученные токены в index_word[index] происходит восстановление из токенов в значения:
''.join([tokenizer.index_word[i] for i in word_tokens]) #проверка привет
Текст восстановлен, значит все ок. Код для нейронной сети:
input1 = Input((num_characters,), name='input_a') #вход первого символа hidden1 = Dense(200, activation='tanh', name='hidden_a')(input1) #преобразование в скрытое пространство dense1 = Dense(500, activation='tanh', name='dense_a')(hidden1) #представление сети о первом символе input2 = Input((num_characters,), name='input_b') #ввод второго символа hidden2 = Dense(200, activation='tanh', name='hidden_b')(input2) #преобразование в скрытое пространство dense2 = Dense(500, activation='tanh', name='dense_ab')(concatenate([dense1, hidden2])) #представление сети о двух символах input3 = Input((num_characters,), name='input_c') #ввод третьего символа hidden3 = Dense(200, activation='tanh', name='hidden_c')(input3) #преобразование в скрытое пространство dense3 = Dense(500, activation='tanh', name='dense_abc')(concatenate([dense2, hidden3])) #представление сети о трех символах output4 = Dense(num_characters, activation='softmax', name='output_d')(dense3) #на основе представления о трех символах предсказываем следующий model = Model(inputs=[input1, input2, input3], outputs=output4) #создаем модель model.summary() plot_model(model, to_file='model.png') model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer=Adam(lr=1e-5))
Визуализация модели показывает, что архитектура сети определена также, как мы планировали в начале.
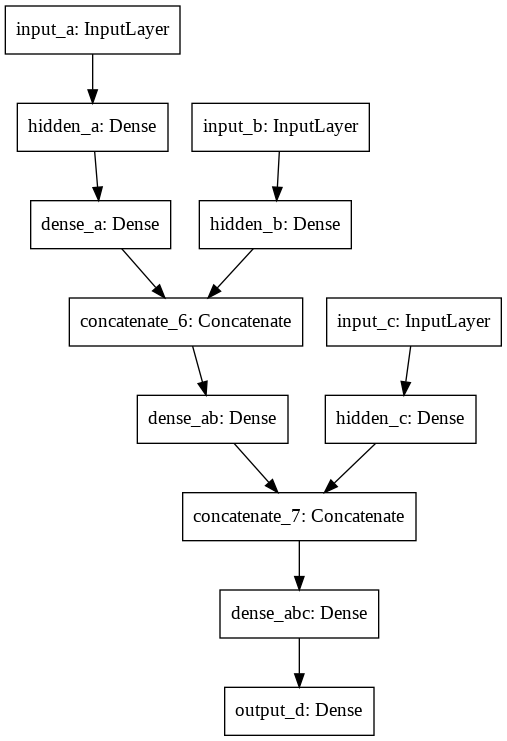
По модели мы должны на вход подать массив с символами X1, X2, X3 и Y — для предсказания. Нужно подготовить соответствующием обучающие массивы.
data = tokenizer.texts_to_matrix(text)
— преобразуем исходный текст в массив OHE. Далее нужно взять из исходного массива три вектора смещенные на 1-цу. В этом случае при взятии индекса некоторого индекса, например index = 5,
- X1[5] — символ в тексте на 5 позиции.
- X2[5] — символ в тексте на 5+1 позиции.
- X3[5] — символ в тексте на 5+2 позиции.
- Y[5] — предсказываемый символ в тексте на 5+3 позиции.
Поскольку предсказание идет по трем символам, то максимально в последовательности будет n символов:
n = data.shape[0]-3 #так как мы предсказываем по трем символам - четвертый, найдем последний номер первого символа
Формируем массивы для обучения:
X1 = data[:n] #первый символ X2 = data[1:n+1] #второй символ X3 = data[2:n+2] #третий символ Y = data[3:] #предсказание четвертого символа
Поскольку предсказываемая буква (четвертая) — это первая буква сдвинутой на единицу последовательности, то:
Y[0] == X3[1]).all() True
Теперь нужно подать полученные вектора для обучения нейронке:
history = model.fit([X1,X2,X3], Y, batch_size=1024, epochs=200)
Нейронка будет подбирать веса слоев так, чтобы предсказывать Y по последовательности X1 -> X2 -> X3. Хотя, при конкатенации слоев все-же последовательность не учитывается, аргументы можно менять местами, но значение на выходе от этого не изменится.
Для проверки предсказания используем простую функцию:
def buildPhrase(res_str, num_sym = 50):
a, b, c = res_str #разбиваем изначальную строку на 3 символа
str_len = num_sym #сколько символов еще создать
for i in range(str_len):
x1 = tokenizer.texts_to_matrix(a) # преобразуем
x2 = tokenizer.texts_to_matrix(b) # символы в
x3 = tokenizer.texts_to_matrix(c) # One-Hot-encoding
pred = model.predict([x1,x2,x3]) #предсказываем OHE четвертого символа
d = tokenizer.index_word[pred.argmax(axis=1)[0]] #получаем ответ в символьном представлении
res_str+=d #дописываем строку
a,b,c = b,c,d #используем предсказание сети, как новый третий символ. остальные смещаем на 1 (второй стал первым, третий стал вторым)
return res_str phrase = buildPhrase('оте')
phrase
'отельно под своим словернул в конечно под своим слове'Предсказывает, конечно, чушь, но и нейронка не бог весть какая наворочная. 🙂
Переходим к рекуррентным сетям
Если посмотреть на схему, то очевидно, что функционально в архитектуре есть несколько блоков, которые выполняют одинаковую работу. Блоки выполняющие одни и те-же операции размечены одинаковыми цветами.

Раз блоки несут одинаковую функциональную нагрузку, то при зацикливании блоков архитектуру можно было бы упростить, зациклив выходы соотвествующих Dense слоев на вход.
По-сути, на схеме представлена развертка рекуррентной сети. Таким образом приходим к рекуррентной архитектуре:
recurrent_model = Sequential() recurrent_model.add(Input((3, num_characters))) #при тренировке в рекуррентные модели keras подается сразу вся последовательность, поэтому в input теперь два числа. 1-длина последовательности, 2-размер OHE recurrent_model.add(SimpleRNN(500)) #рекуррентный слой на 500 нейронов recurrent_model.add(Dense(num_characters, activation='softmax')) recurrent_model.summary()

Слой SimpleRNN, по сути, содержит один Dense слой которому на вход приходят некоторые значения, они проходят через Dense слой, но выход этого слоя конкатенируется с входом.
При использовании рекуррентной сети для решения задачи количество параметров сети уменьшается в несколько раз, хотя количество нейронов используется столько-же (500), сколько в dense слое для смешивания представлений о предыдущей последовательности и новом символе.
При этом качество предсказания рекуррентной сетью остается примерно на том-же уровне, как и развернутой на dense слоях.
Поскольку на рекуррентную нейронку подается одна матрица на вход, необходимо объединить X1, X2, X3 в одну матрицу:
joined = np.hstack([X1, X2, X3]) joined.shape (668450, 102)
На выходе получим склейку по горизонтали X1, X2, X3. Каждый из этих векторов — это OHE длиной 34. На вход рекуррентной сети подается трехмерная матрица (куб), поэтому нужно сделать reshape:
X_rnn = joined.reshape([X1.shape[0], 3, num_characters]) X_rnn.shape (668450, 3, 34)
Соответственно, в матрице 668450 строк. Каждая строка размерностью 3 (количество элементов по которым происходит предсказание следующего) и каждый этот элемент состоит из 34 (OHE).
В данном случае на вход подавали символы. Можно подавать слова и тогда сеть будет предсказывать последовательность слов.