В предыдущей статье я детально рассмотрел пример анализа временного ряда с помощью сверточной нейронной сети.
В этой статье я сделаю небольшое упрощение функции подготовки временного ряда для анализа сверточной нейронной сетью. Опущу теорию в части зачем выполняется такая подготовка, поскольку детали подробно разобраны в предыдущей статье.
Сформируем тестовую последовательность.
num = 20
xData = np.arange(0, num).reshape(num,1)
print(xData)
stepsForward = 1
xLen = 5
valLen = 3
xChannels = 0
print("xData.shape", xData.shape)
print("Range:", xData.shape[0] - xLen + 1 - stepsForward)[[ 0] [ 1] [ 2] ... [16] [17] [18] [19]] xData.shape (20, 1) Range: 15
Немного подправлю функцию для нормализации данных, добавив возможность указать тип нормализации -1, т.е. без нормализации. При этом функция просто возвращается столбцы отобранные по переданному списку Channels:
#data - Numpy array
#Normalization = 0 - нормальное распределение, 1 - к отрезку [0;1], -1 - не нормализовывать
def DataNormalization(data, Channels, Normalization):
#Выбираем тип нормализации x
#0 - нормальное распределение
#1 - нормирование до отрезка 0-1
if (Normalization == 0):
scaler = StandardScaler()
if (Normalization == 1):
scaler = MinMaxScaler()
#Берём только те каналы, которые указаны в аргументе функции
resData = data[:,Channels]
if (len(resData.shape) == 1): #Если размерность входного массива - одномерный вектор,
print("Add one dimension")
resData = np.expand_dims(resData, axis=1) #то добавляем размерность
if (Normalization == -1):
scaler = np.zeros(resData.shape[0])
return (resData, scaler)
#Обучаем нормировщик
scaler.fit(resData)
#Нормируем данные
resData = scaler.transform(resData)
return (resData, scaler)Теперь сама функция по «раскусыванию» временного ряда для подготовки к передаче на сверточную сеть:
#Функция "раскусывания" данных для временных рядов
#data - данные
#xLen - размер "окна", по которому предсказываем
#xChannels - лист, номера каналов, по которым делаем анализ
#yChannels - лист, номера каналов, которые предсказываем
#stepsForward - на сколько шагов предсказываем в будущее
# если 1 - то на 1 шаг, можно использовать только при одном канале, указанном в yChannels
#xNormalization - нормализация входных каналов, 0 - нормальное распределение, 1 - к отрезку [0;1], -1 - не нормализовывать
#yNormalization - нормализация прогнозируемых каналов, 0 - нормальное распределение, 1 - к отрезку [0;1], -1 - не нормализовывать
#returnFlatten - True - если на выходе получить одномерный вектор для Dense сетей
#valLen - сколько примеров брать для проверочной выборки (количество для обучающей посчитается автоматиески)
#convertToDerivative - bool, преобразовывали ли входные сигналы в производную
def getTrainSeq(data, xLen, xChannels, yChannels, stepsForward, xNormalization, yNormalization, returnFlatten, valLen, convertToDerivative):
#Если указано превращение данных в производную
#То вычитаем поточечно из текущей точки предыдущую
if (convertToDerivative):
data = np.array([(d[1:]-d[:-1]) for d in data.T]).copy().T
else:
if isinstance(data,(pd.core.series.Series, pd.core.frame.DataFrame)): #Проверяем, если на входе Pandas - то, берем values, для получения numpy Array
print("Convert Pandas.Series to Numpy array")
data = data.values
#Нормализуем данные
(xData, xScaler) = DataNormalization(data, xChannels, xNormalization)
(yData, yScaler) = DataNormalization(data, yChannels, yNormalization)
valLen = valLen + xLen - 1 + stepsForward #Вычисляем сколько данных с конца нужно взять, чтобы размерность xVal/yVal была valLen
#Разбивка входного ряда до обработки
xTrain = xData[:xData.shape[0]-valLen]
yTrain = yData[:yData.shape[0]-valLen]
xVal = xData[xData.shape[0]-valLen:]
yVal = yData[yData.shape[0]-valLen:]
xTrain = np.array([xTrain[i:i + xLen, xChannels] for i in range(xTrain.shape[0] - xLen + 1 - stepsForward)])
yTrain = np.array([yTrain[i:i + stepsForward, yChannels] for i in range(xLen, yTrain.shape[0] + 1 - stepsForward)])
xVal = np.array([xVal[i:i + xLen, xChannels] for i in range(xVal.shape[0] - xLen + 1 - stepsForward)])
yVal = np.array([yVal[i:i + stepsForward, yChannels] for i in range(xLen, yVal.shape[0] + 1 - stepsForward)])
#Если в функцию передали вернуть flatten сигнал (для Dense сети), то xTrain и xVal превращаем в flatten
if (returnFlatten == True):
xTrain = np.array([x.flatten() for x in xTrain])
xVal = np.array([x.flatten() for x in xVal])
return (xTrain, yTrain), (xVal, yVal), (xScaler, yScaler)Протестируем работу функции на тестовом numpy.array:
xNormalization = -1
yNormalization = -1
xChannels = [0]
yChannels = [0]
convertToDerivative = False
returnFlatten = False
stepsForward = 1
xLen = 5
valLen = 3
(xTrain, yTrain), (xVal, yVal), (xScaler, yScaler) = getTrainSeq(xData, xLen, xChannels, yChannels, stepsForward, xNormalization, xNormalization, returnFlatten, valLen, convertToDerivative)
print("xTrain:\r\n", xTrain)
print("yTrain:\r\n", yTrain)
print("xVal:\r\n", xVal)
print("yVal:\r\n", yVal)Как и указывалось, valLen = 3, т.е. на проверочную выборку отводится 3, а остальное на обучающую выборку.
xTrain: [[ 0 1 2 3 4] [ 1 2 3 4 5] [ 2 3 4 5 6] [ 3 4 5 6 7] [ 4 5 6 7 8] [ 5 6 7 8 9] [ 6 7 8 9 10]] yTrain: [[ 5] [ 6] [ 7] [ 8] [ 9] [10] [11]] xVal: [[12 13 14 15 16] [13 14 15 16 17] [14 15 16 17 18]] yVal: [[17] [18] [19]]
Нейронная сеть будет пытаться найти закономерности между каждой серией X длиной xLen и Y длиной stepsForward. Если
xLen = 300 #Анализируем по 300 прошедшим точкам
stepsForward = 10 #Тренируем сеть для предсказания на 10 шагов вперед
xChannels = range(data.shape[1]) #Используем все входные каналы
yChannels = 0 #Предказываем только open канал
xNormalization = 0 #Нормируем входные каналы стандартным распределением
yNormalization = 0 #Нормируем выходные каналы стандартным распределением
valLen = 30000 #Используем 30.000 записей для проверки0
returnFlatten = False #Если True, то вернуть одномерные векторы, если False, то двумерные
convertToDerivative = False #Не True, то превращать в производную
(xTrain, yTrain), (xVal, yVal), (xScaler, yScaler) = getTrainSeq(data, xLen, xChannels, yChannels, stepsForward, xNormalization, yNormalization, returnFlatten, valLen, convertToDerivative)
#Выводим размеры данных для проверки
print("xTrain.shape:", xTrain.shape)
print("yTrain.shape:", yTrain.shape)
print("xVal.shape:", xVal.shape)
print("yVal.shape:", yVal.shape)Convert Pandas.Series to Numpy array Add one dimension xTrain.shape: (136745, 300, 1) yTrain.shape: (136745, 10) xVal.shape: (30000, 300, 1) yVal.shape: (30000, 10)
Прогноз курса GBPUSD по данным с bloomberg
Подгружаем данные спарсенные с bloomberg по курсам валют в csv файл.
#Считываем данные с помощью pandas
base_data = pd.read_csv('bloomberg.txt', sep=';')
print(base_data.shape)Отбираем данные только по курсам GBPUSD:
GBPUSD = base_data[base_data['ticker'] == 'GBPUSD']
Парсим данные из колонки date_time в соответствии с шаблоном и пересохраняем колонку ‘date_time’.
GBPUSD['date_time'] = pd.to_datetime(GBPUSD['date_time'], format='%d.%m.%Y %H:%M:%S') GBPUSD.info()
Теперь в этой колонке не строка, а тип datetime64.
Int64Index: 167363 entries, 4 to 500413 Data columns (total 3 columns): date_time 167363 non-null datetime64[ns] ticker 167363 non-null object value 167363 non-null float64 dtypes: datetime64[ns](1), float64(1), object(1)
Поскольку после фильтрации данных в index выпады, переиндексируем массив, присвоив колонку с типом дата в индекс и попутно удалив колонки ‘date_time’ и ‘ticker’ за ненадобностью.
data = GBPUSD data = data.drop(columns=['date_time','ticker'], axis=1) data.index = GBPUSD.date_time
Отрисуем временной ряд:
fig, ax = plt.subplots(1, 1, figsize=(15, 8))
data.plot(ax=ax, lw=.5)
#ax.set_ylim(min, max)
ax.set_xlabel('Date')
ax.set_ylabel('GBPUSD rate')
Отмечу, что по оси x отображаются даты, а не номера отсчетов.
Если сделать прогноз временного ряда курсов GBPUSD взятых с bloomberg на 10 шагов вперед, то визуально видно, что прогноз довольно плотно огибает исходный ряд.
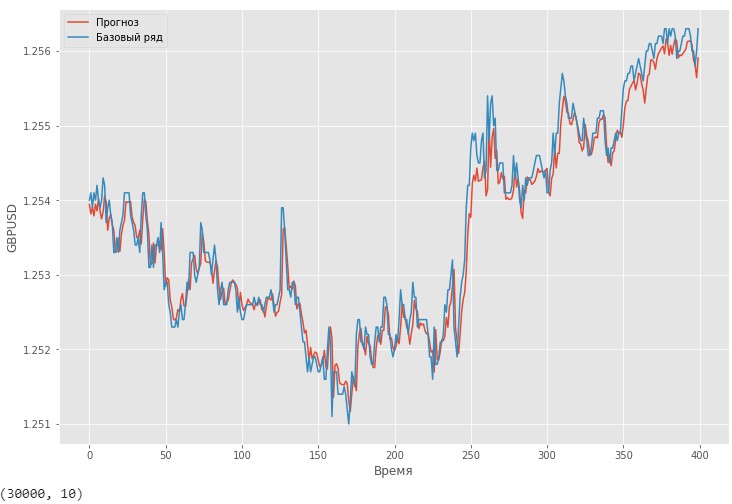
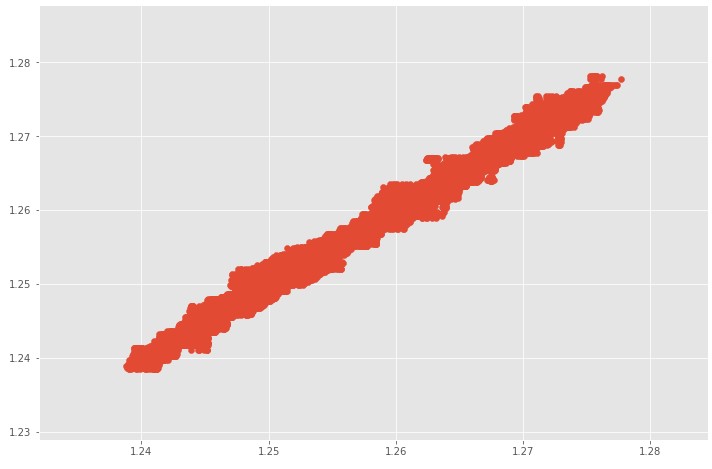
Scatter оригинального временного ряда и прогноза на 10 шаговпо проверочной выборке.
Чтобы нейронка смогла выявлять какие-то сезонные закономерности нужно в качестве каналов добавить параметры даты и/или времени. Как это сделать? Подавать параметры даты лучше по отдельности. Например, 22.12.2019 11:59:55 -> 5 каналов: 22;12;11;59;55. Нужно ли подавать год — это вопрос.
При наличии ежегодного цикла (можно выявить с помощтю преобразования Фурье) нейронке достаточно информации из столбца месяц, чтобы вытащить информацию о годовой сезонности.
Если во временном ряде присутствует сезонность с периодом больше, чем 1 год, возможно, в качестве отдельного канала стоит добавить год.
Пример добавления в Pandas.DataFrame колонок с датами с последующей сортировкой колонок, чтобы можно было исключить колонку с годом.
GBPUSD['Month'] = GBPUSD['date_time'].dt.month GBPUSD['Day'] = GBPUSD['date_time'].dt.day GBPUSD['Hour'] = GBPUSD['date_time'].dt.hour GBPUSD['Minute'] = GBPUSD['date_time'].dt.minute GBPUSD['Second'] = GBPUSD['date_time'].dt.second GBPUSD['Year'] = GBPUSD['date_time'].dt.year GBPUSD = GBPUSD.drop(columns=['date_time'], axis=1) GBPUSD.columns = ['GBPUSD', 'Month', 'Day', 'Hour', 'Minute', 'Second', 'Year']
День недели/месяц, некоторые флаги событий (например, праздник, выходной или обычный день), можно подавать как числовые метрики: 1/0 — праздник/не праздник; 1-7 день недели.