В предыдущей статье я очень подробно разобрал построение архитектуры нейронной сети на dense слоях в Keras и Tensorflow. В этой статье рассмотрю сверточные (convolutional) слои.
Эта статья, как и предыдущая, использует материалы лекций Сергея Кузина читаемых в «Университете искусственного интеллекта», но дополнена моими комментариями и материалами из других источников для лучшего понимания темы.
Сверточный слой (convolutional layer)
Архитектура сверточных сетей предложена Яном Лекуном в 1988 году[1]. Предназначалась, главным образом, для анализа изображений.
Если взять для примера черно-белое изображение, то это некоторая матрица, например, размером 100х100х1 пикселей. Если бы изображение было цветным (RGB), то размерность была бы 100х100х3, т.е. фактически три картинки с цифрами отражающими градации каждого цвета.
Дискретная свертка
Сверточный слой реализует операцию дискретной свертки, широко применяемый в цифровой обработке сигналов. При этой операции одна из функций (ядро свертки) сдвигается относительно другой и производится перемножение отсчетов и суммирование произведений.
Ядро свертки — это матрица определенной ширины kW и высоты kH. Чаще всего матрица квадратная, но в общем случае kW может быть не равно kH.
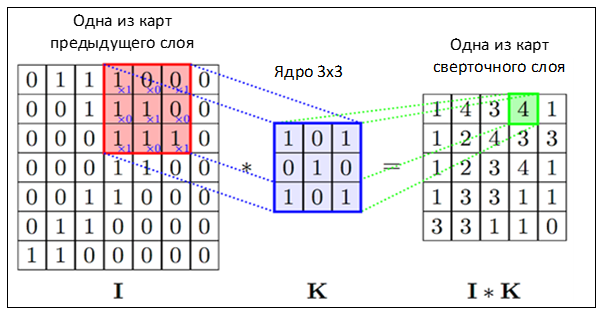
После операции свертки на выходе формируется выходная карта (матрица) признаков — output feature maps или просто карта. Исходное изображение — это также матрица (карта), которая обрабатывается ядром свертки:
- Через ядро свертки, как через окно (фильтр), идет «просмотр» исходной матрицы.
- Элементы исходной матрицы перемножаются поэлементно на соответствующие значения в ядре свертки. Например, на рисунке ниже результаты перемножения указаны синим на первой карте: x1, x0.
- Полученные произведения суммируются. Например, после суммирования произведений на картинке в результате получилась цифра 4.
- Полученные значения — карта признаков, подаваемая на следующий слой.
Математически операция дискретной свертки представляется в виде формулы:

Чтобы на выходе получилась матрица, ядро свертки сдвигают на некоторый шаг (stride) по вертикали и горизонтали. Шаг может быть одинаковым для смещения по оси х и y, а может различаться.
Например, свертка матрицы с ядром свертки:
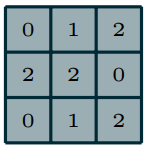
Дает следующие значения:
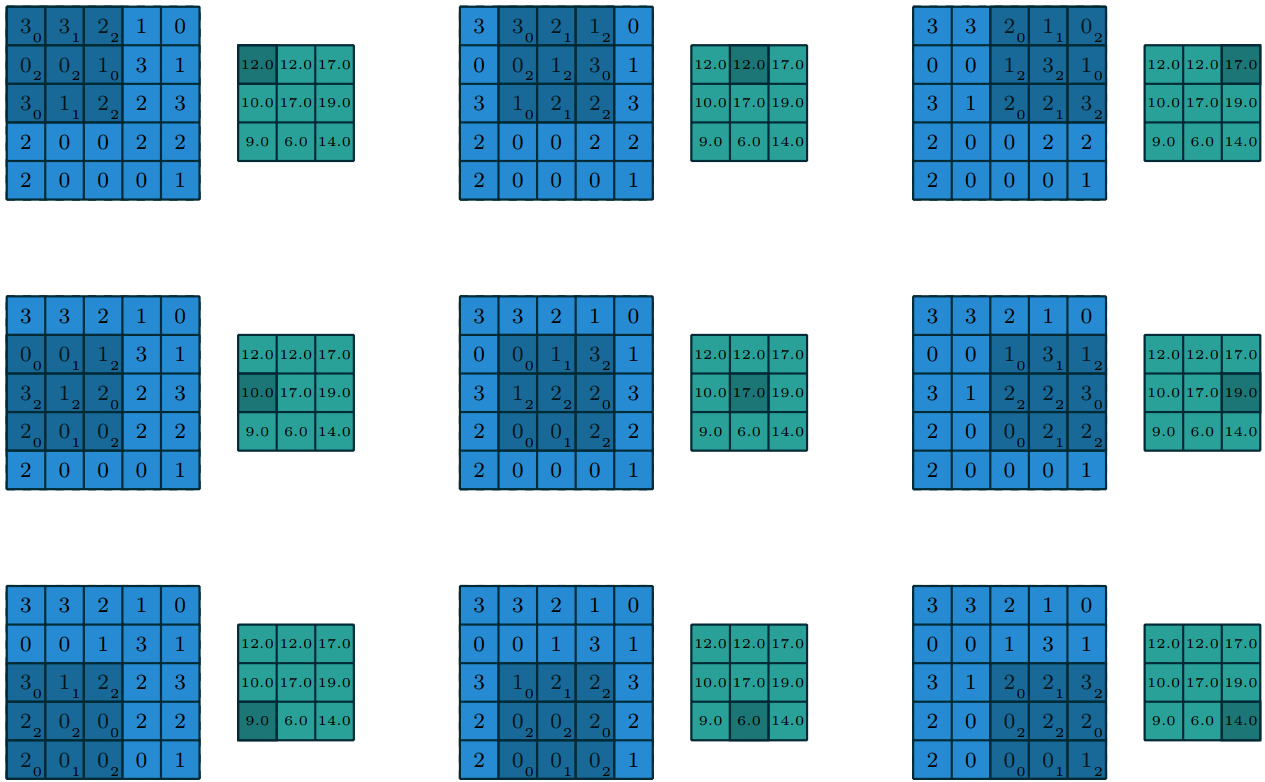
При сдвиге ядра свертки произойдет уменьшение размера получаемой карты. Размерность выходной карты признаков будет определяться по следующей формуле.
(Wout, Hout) = (Win — Wk + 1, Hin — Hin + 1), где
- (Wout, Hut) — вычисляемый размер сверточной карты;
- Win — ширина предыдущей карты;
- Hin — высота предыдущей карты;
- Wk — ширина ядра;
- Hk — высота ядра;
Например, если исходное изображение было 100х100 и по нему прошлись ядром свертки (5, 5), то на выходе будет матрица (100 — 5 + 1, 100 — 5 + 1) = (96, 96). Более общая формула следующая:
Padding = «same»
В некоторых случаях уменьшение выходной карты признаков неудобно. Например, нужно согласовывать размеры матриц. Чтобы размерность карты после свертки оставалась той-же, добавляют padding: матрицу обрамляют нулями (zero-padding).
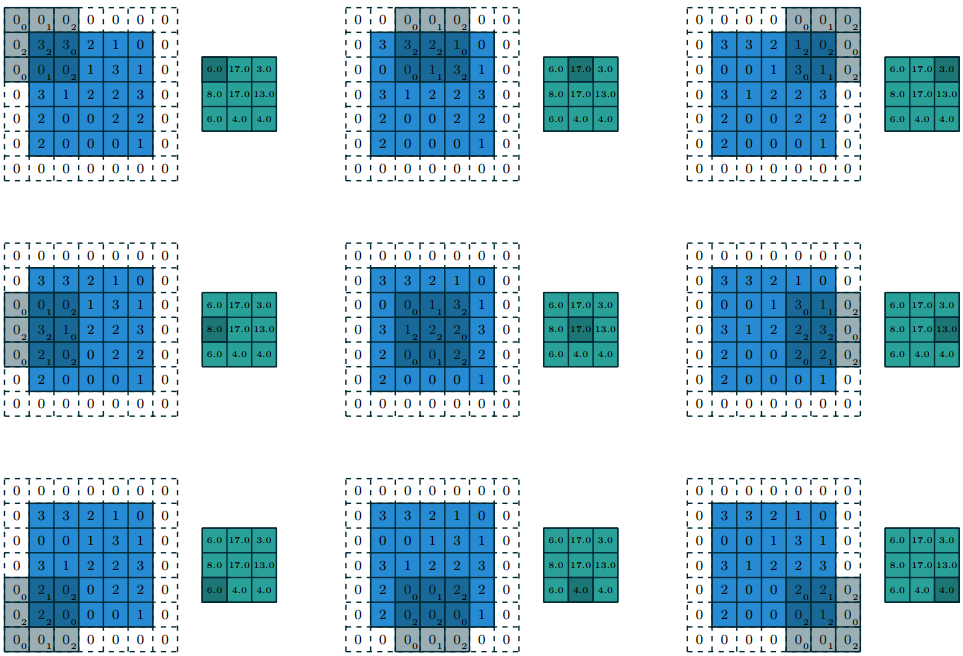
Ядро свертки скользит не с начала реальных значений входной матрицы, а с обрамления/набивки (padding-а), поэтому размер выходнйо карты признаков не уменьшается. На практике встречаются и другие варианты padding-а.

Если при преобразовании padding > 0 и stride > 1, то общая формула для расчета размерности после свертки:
- Вход: тензор mH х mW х Fin
- Выход: тензор Hout x Wout x Fout
- 4 гиперпараметра:
- F — число фильтров
- Hk, Wk — пространственный размер фильтров
- S — шаг
- P — количество заполнения нулями
- Соотношение размеров входа и выхода:
- Hout = (Hin — Hk + 2P)/S + 1
- Wout = (Win — Wk + 2P)/S + 1
- Fout = F
В случае если размерность входной матрицы, например, 3D, то ядро свертки будет представлять кубойд, который будет сдвигаться по ширине, высоте и глубине. При свертке исходной 3D матрицы c кубойдом на выходе получится двумерная карта признаков.
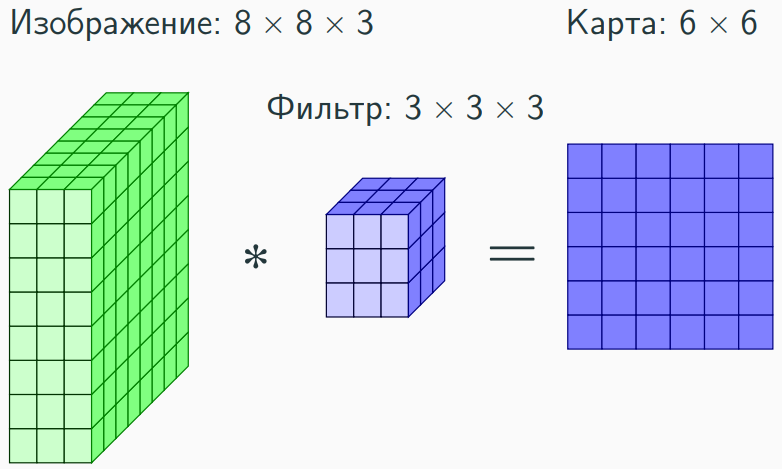
Размерность карты признаков на выходе 6 х 6 x 1, поскольку, S = 1, P = 0, Wk = 3, Hk = 3, Win = 3, Hin = 8:
- Сдвиг ядра 3 х 3 вдоль оси z (8 х 3) = 8 — 3 + 1 = 6.
- Сдвиг ядра 3 х 3 вдоль оси y (8 х 3) = 8 — 3 + 1 = 6.
- Сдвиг ядра 3 х 3 вдоль оси x (3 х 3) = 3 — 3 + 1 = 1.
У сверточного слоя есть параметр filters (F) — это количество уникальных фильтров (ядер свертки), которые применяются к входной карте для выполнения операции свертки.
На выходе образуется несколько карт признаков по количеству фильтров (F). Каждый фильтр (ядро свертки) настраивается на выявление какой-то определенной фичи (признака) в исходной матрице.

Веса ядра свертки фиксированны для фильтра. Оптимизатор подбирает параметры каждого фильтра так, чтобы минимизировать выбранный loss.
Например, после тренировки сети получили ядро (фильтр) 7х7, которое выявляет характерный изгиб на изображении мыши. Если на изображении такой изгиб присутствует, то при выполнении оперции дискретной свертки в определенном месте карты получится большое значение, если же признак не обнаружен, то значение будет небольшим.

Pooling
— это ещё один строительный элемент в построении CNN. Операция pooling уменьшает размер карты признаков, используя некоторую функцию для объединения ближайших элементов матрицы. В качестве функции может использоваться среднее арифметическое или максимум.
При выполнении операции pooling, как и в случае со сверткой, окно определенного размера скользит вдоль оси и над содержимым попавшем в окно выполняется pooling function.
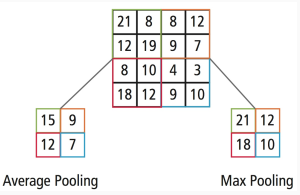
Если рассмотреть эту операцию более подробно, то в чем-то она напоминает операцию дискретной свертки:
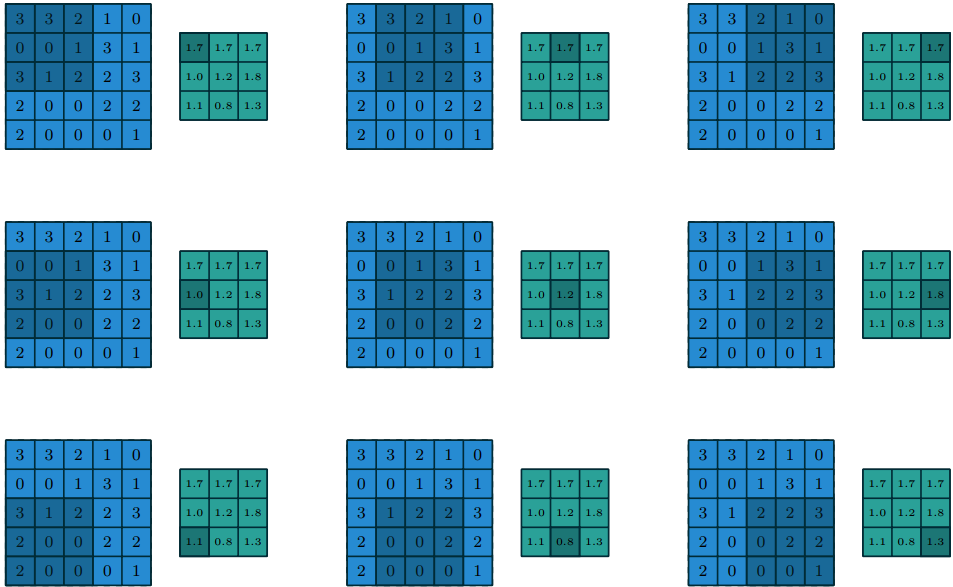
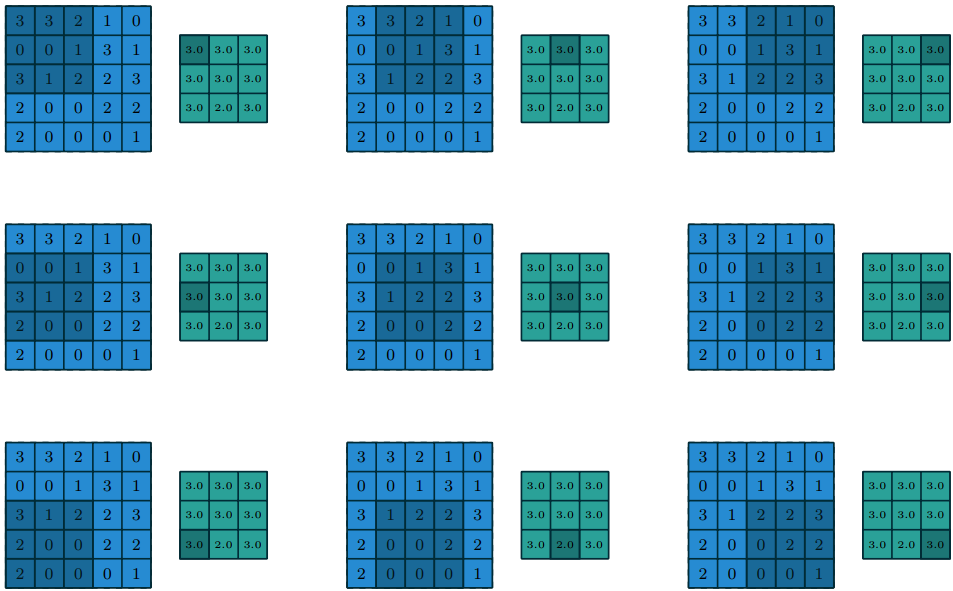
При pooling размерность выходной матрицы вычисляется по формуле:
- Wout = (Win — Wk)/S + 1
- Hout = (Hin — Hk)/S + 1
Convolutional layers на Tensorflow
После подробного разбора теории создадим нейронную сеть на сверочных слоях. Код к примеру. Отмечу, что, как правило, сверточные (conviolutional) слои используются в паре с полносвязными (dense), поскольку на выходе архитектуры нередко требуется выполнить классификацию. Поэтому сверточные слои соединяются с dense на выходе которых уже выдается, например, вероятность отнесения объекта к тому или иному классу.
ОТмечу, что TensorFlow — штука достаточно капризная, поэтому может потребоваться откат к предыдущей версии Tensroflow на котором пример работает нормально.
!pip3 uninstall tensorflow-gpu==1.15.0 !pip3 install tensorflow-gpu==1.13.1
В Keras сверточный слой добавляется следующим образом:
model.add(Conv2D(32, (5,5)), где F = 32 - количество фильтров, Wk = 5, Hk = 5. При (Win, Hin) = (100, 100) -> (Wout, Hout) = (96, 96)
Чтобы сохранить размерность выходной карты признаков:
model.add(Conv2D(32, (5,5), padding = 'same')
Можно указать шаг (stride):
model.add(Conv2D(32, (5,5), strides = 2, padding = 'same') тогда При (Win, Hin) = (100, 100) -> (Wout, Hout) = (50, 50)
- В Tensorflow перемещение ядра свертки по слоям возможно не только по оси x и y, как в Keras, но и z. Можно применять операцию свертки к определенным каналам по оси Z, например, брать каждый 3 слой.
- В Tensorflow можно указать применять сверточный слой к определенным batch-ам. Это может быть полезно при обработке видео.
Предположим, что на входе x — изображение 28 х 28 х1 , которое уже было преобразовано ранее reshape-ом в вектор 784 х 1. Поэтому нужно будет сделать обратное преобразование, либо использовать исходное изображение.
# Параметры сети
learningRate = 0.001
epochs = 10
batchSize = 200
dropout = 0.3
# Объявляем placeholders для тренировочного набора
# Размерность x = 28 x 28 пикселей = 784
x = tf.placeholder(tf.float32, [None, 784]) # None пока неизвестное количество batch-ей
# Трансформируем х в 4х мерный тензор [количество объектов в сете, ширина, высота, количество каналов]
xShaped = tf.reshape(x, [-1, 28, 28, 1]) # batchSize = -1, т.к. мы точно знаем другие параметры данного сета, так что
# tensorFlow автоматически распределит равномерно по batch-ам
# Объявляем выход placeholder, т.е. 10 цифр
y = tf.placeholder(tf.float32, [None, 10])Зададим функцию для построения сверточного слоя:
- inputData — входные данные,
- numInputChannels — количество входных каналов. Например, для RGB изображения оно равно 3-м.
- numFilters — это количество фильтров (F),
- filterShape — размерность ядра свертки (Wk, Hk),
- poolShape — размерность ядра MaxPooling.
Размерность матрицы для весов сверточного слоя определяются — convFiltShape. Поскольку для слоя задано нектрое количество фильтров F x Wk x Hk — количество весов для одного слоя изображения. В случаеесли numInputChannels = 3, то полученую размерность нужно будет утроить, поскольку каждое ядро свертки (фильтр) будет применятся к каждому каналу в изображении.
Нейрон смещения соединится только с каждым фильтром, поэтому его размерность будет равна количеству фильтров.
Для сверточного слоя strides = [1, 1, 1, 1] — шаги по батчам и затем по трем каналам: x, y, z.
Для maxpooling strides = [1, 2, 2, 1] — шаги по батчам. Затем через два шага по x, y, т.е. размерность по x и y уменьшится в два раза. По оси z выбираются все каналы.
def newConvLayer(inputData, numInputChannels, numFilters, filterShape, poolShape, name):
# Параметры фильтра сверточного слоя
convFiltShape = [filterShape[0], filterShape[1], numInputChannels,
numFilters] #высота, ширина, количество входящих каналов, количество фильтров
# Инициализируем веса и отклонение для сверточного слоя
weights = tf.Variable(tf.truncated_normal(convFiltShape, stddev=0.03), # нормальное распределение+усечение с точки насыщения sigmoid-функции,т.е. когда нейронка перестает учиться
name=name+'_W')
bias = tf.Variable(tf.truncated_normal([numFilters]), name=name+'_b')
# Параметры сверточного слоя
outLayer = tf.nn.conv2d(inputData, weights, [1, 1, 1, 1], padding='SAME') # padding = SAME,
# т.е. формат [количество объектов в сете, ширина, высота, количество каналов] сохраняется
# Добавляем смещение
outLayer += bias
# Применяем функцию активации ReLU
outLayer = tf.nn.relu(outLayer)
# Применяем max pooling
ksize = [1, poolShape[0], poolShape[1], 1]
strides = [1, 2, 2, 1]
outLayer = tf.nn.max_pool(outLayer, ksize=ksize, strides=strides,
padding='SAME')
return outLayerС помощью этой функции создаем сверточные слои. У первого слоя:
- Поскольку у MNIST количество слоев в изображении 1, то первый параметр будет 1.
- 32 — количество фильтров (ядер свертки).
- [5, 5] — размерность ядра свертки.
- [2, 2] — размерность ядра maxpooling.
# Создаем сверточные слои, используя нашу функцию layer1 = newConvLayer(xShaped, 1, 32, [5, 5], [2, 2], name='layer1')
На выходе из-за maxpooling размерность карты признаков с 28х28 уменьшилась до 14х14. У второго слоя:
- Поскольку на выходе первого сверточного слоя количество слоев равно количеству фильтров, то количество каналов будет 32.
- 64 — количество фильтров во втором слое.
- [5, 5] — размерность ядра свертки.
- [2, 2] — размерность ядра maxpooling.
layer2 = newConvLayer(layer1, 32, 64, [5, 5], [2, 2], name='layer2')
На выходе из-за maxpooling размерность карты признаков с 14 х 14 уменьшилась до 7 х 7 и количество фильтров 64, значит матрица будет размерностью 7 х 7 х 64. Для подачи на dense слой нужно сделать flatten. Аналога слоя Flatten в Tensorflow нет, поэтому используем обычный reshape:
flattened = tf.reshape(layer2, [-1, 7 * 7 * 64])
Добавляем два полносвязных слоя. Подробно про dense слои в Tensorflow я разбирал в предыдущей статье.
Первый слой на 1000 нейронов с активационной функцией Relu и слоем dropout.
# В первом слое задаем матрицу весов, bias(отклонение) и применяем функцию активации ReLU Wd1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1000], stddev=0.03), name='Wd1') # матрица со значениями по нормальному распределению и стандартным отклонением 0.3 Bd1 = tf.Variable(tf.truncated_normal([1000], stddev=0.01), name='Bd1') # вектор отклонений, 1000 - количество нейронов в скрытом слое denseLayer1 = tf.matmul(flattened, Wd1) + Bd1 denseLayer1 = tf.nn.relu(denseLayer1) denseLayer1 = tf.nn.dropout(denseLayer1, dropout)
Второй слой на 10 нейронов для классификации с активационной функцией softmax.
# Второй слой аналогичный, но 10 - количество нейронов не скрытого слоя, а выходного Wd2 = tf.Variable(tf.truncated_normal([1000, 10], stddev=0.03), name='Wd2') Bd2 = tf.Variable(tf.truncated_normal([10], stddev=0.01), name='Bd2') denseLayer2 = tf.matmul(denseLayer1, Wd2) + Bd2 y_ = tf.nn.softmax(denseLayer2)
Функция loss используется такая-же, как в предыдущей статье.
crossEntropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=denseLayer2, labels=y))
В данном случае в качестве оптимизатора импользуется TensorFlow аналог Adam.
# Задаем оптимайзер optimiser = tf.train.AdamOptimizer(learning_rate=learningRate).minimize(crossEntropy)
Точность считается также, как в предыдущей статье:
# Определение accuracy correctPrediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correctPrediction, tf.float32))
И запускаем тренировку сети:
# Запускаем сессию
sess = tf.Session()
sess.run(initOp)
totalBatch = int(len(mnist.train.labels) / batchSize)
for epoch in range(epochs):
avgLoss = 0 # сюда добавляем среднее значение
for i in range(totalBatch): # для каждого batch
batchX, batchY = mnist.train.next_batch(batch_size=batchSize)
_, c = sess.run([optimiser, crossEntropy], # т.к. нам не нужно для каждой итерации запоминать вычисления непосредственно самого оптимизатора, то _
# для функции потерь - присваеваем переменную c
feed_dict={x: batchX, y: batchY})
avgLoss += c / totalBatch # вычисляем среднюю ошибку
testAcc = sess.run(accuracy,
feed_dict={x: mnist.test.images, y: mnist.test.labels}) # подсчет точности
print("Epoch:", (epoch + 1), "Loss =", "{:.3f}".format(avgLoss), "test accuracy:"," {:.3f}".format(testAcc))
print("Точность:",sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})*100,"%")
sess.close()В TensorBoard элементов много:
