Многим разработчикам комфортнее работать на ноутбуках, которые нередко обладат достаточно слабыми GPU, а тренировка нейронных сетей быстрее всего идет на многоядерных графических картах. Как разрешить это противоречие?
Можно использовать два варианта:
- Облачные сервера с GPU. Из наиболее распространенных бесплатных: Google Colab, Kaggle. Но там есть ограничение по времени тренировки сети и по аппаратным ресурсам. Скорее всего переподписка значительная, поэтому производительность может быть довольно низкой. Не раз сталкивался с просадкой скорости тренировки в несколько раз. Из платных относительного недорогие варианты GPU облачных серверов (хостингов): FloydHub, PaperSpace, ExoScale, Alibaba Cloud. Добротное сравнение GPU хостингов.
- Внешний eGPU корпус с видеокартой и ноутбук с портом Thunderbolt 3 (теоретическая производительность до 40 Gb/s, реальная скорее 5 Гб/с). Сравнение eGPU платформ здесь + производительная видеокарта (не Tesla, она серверная с пассивным охлаждением), подобрать которую можно здесь. Собственно, под производительные «горячие» и длинные видеокарты основной вариант — Razer Core X, поддерживающий энергопотребление видеокарт до 500 Вт.
Естественно, в данном случае есть некоторые сомнения по поводу производительности eGPU, поскольку Thunderbolt интерфейс — узкое место по скорости.
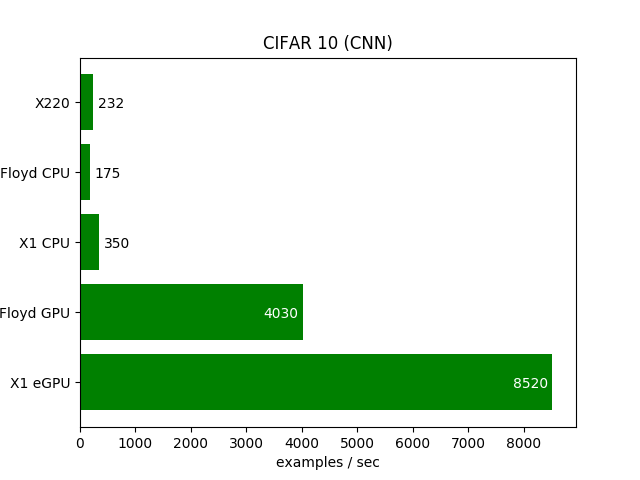
Мне удалось найти лишь одно сравнение облачных GPU серверов на видеокартах Tesla K80 12 GB VRAM (спаренный GPU, суммарно 2х12 Gb) и eGPU с картой Nvidia GTX 1070Ti 8GB VRAM (через eGPU Sonnet Breakaway).
Честно говоря результаты довольно удивительные. Во всех тестах комбинация ноутбук + eGPU с не самой производительной картой Nvidia GTX 1070Ti выдавал почти вдвое выше скорость, нежели супермощные Tesla в облаке.
Вероятнее всего ресурсы GPU сервер деляться между подписчиками сервиса, т.е. в эксклюзивное пользование видеокарта если и предоставляется, то на короткое время. Возможно пользователям отдается в пользование ограниченное число ядер GPU, поэтому есть просадка.


Финансы
Сравним затраты на оба варианта реализации лаборатории для работы на ноутбуке:
| Наименование | eGPU | FloydHub GPU |
| eGPU Razer Core X | 300 USD | — |
| Nvidia GTX 1070Ti 8GB | 430 uSD | — |
| GPU | — | 9 USD/мес * 12 мес = 108 USD/год |
| Сервер | — | 1.2 USD/час * 8 ч * 21 день = 201 USD/мес. * 12 мес = 2419 USD / год |
| Итого: | 730 USD / 3 года = 243 USD/год | 2527 USD/год |
Получаем, что в случае eGPU единовременные затраты составят порядка 730 USD. При этом средний срок эксплуатации решения 3 года или 243 USD/год.
Получаем, что аренда GPU сервера обходится примерно в 10 раз дороже, чем приобретение eGPU + видеокарты. Это без учета в два раза меньшей производительности, скорее всего вызванной переподпиской ресурсов GPU.
Отмечу, что это весьма недорогой сервис по сдаче GPU в аренду. Если смотреть решения, например, от IBM, то там ежемесячная стоимость начинается от 1200 USD на виртуальном сервере. Но при этом решении видеокарта предоставляется в эксклюзивное пользование.
Видеокарты с 8 Gb недостаточно для решения сложных задач deep learning. Новая Nvidia M6000 с 24 Gb VRAM будет стоить около 2350 USD. Совокупные затраты в этом случае вырастут примерно до 2650 USD единовременно и окупятся примерно через год, если сравнивать с арендой GPU сервера. В этом случае уже надо смотреть какие затраты предпочтительнее CAPEX в случае с пприобретением eGPU или OPEX при аренде облачных GPU.
Примеры тестирования cloud GPU
Скрипт для тестирования в Colab от http://ai-benchmark.com/alpha:
!pip install ai-benchmark from ai_benchmark import AIBenchmark results = AIBenchmark().run()
Пример результатов по Colab не Pro версия (20.06.2020):
* TF Version: 2.2.0 * Platform: Linux-4.19.104+-x86_64-with-Ubuntu-18.04-bionic * CPU: Intel(R) Xeon(R) CPU @ 2.00GHz * CPU RAM: 13 GB * GPU/0: Tesla T4 * GPU RAM: 13.6 GB * CUDA Version: 10.1 * CUDA Build: V10.1.243 The benchmark is running... The tests might take up to 20 minutes Please don't interrupt the script 1/19. MobileNet-V2 1.1 - inference | batch=50, size=224x224: 69.8 ± 5.5 ms 1.2 - training | batch=50, size=224x224: 322 ± 2 ms 2/19. Inception-V3 2.1 - inference | batch=20, size=346x346: 97.0 ± 2.0 ms 2.2 - training | batch=20, size=346x346: 364 ± 2 ms 3/19. Inception-V4 3.1 - inference | batch=10, size=346x346: 99.5 ± 1.9 ms 3.2 - training | batch=10, size=346x346: 383 ± 2 ms 4/19. Inception-ResNet-V2 4.1 - inference | batch=10, size=346x346: 136.4 ± 1.0 ms 4.2 - training | batch=8, size=346x346: 402 ± 3 ms 5/19. ResNet-V2-50 5.1 - inference | batch=10, size=346x346: 64.9 ± 1.0 ms 5.2 - training | batch=10, size=346x346: 228 ± 1 ms 6/19. ResNet-V2-152 6.1 - inference | batch=10, size=256x256: 90.0 ± 1.5 ms 6.2 - training | batch=10, size=256x256: 308 ± 2 ms 7/19. VGG-16 7.1 - inference | batch=20, size=224x224: 168 ± 2 ms 7.2 - training | batch=2, size=224x224: 234 ± 1 ms 8/19. SRCNN 9-5-5 8.1 - inference | batch=10, size=512x512: 124.3 ± 1.0 ms 8.2 - inference | batch=1, size=1536x1536: 132 ± 2 ms 8.3 - training | batch=10, size=512x512: 457 ± 3 ms 9/19. VGG-19 Super-Res 9.1 - inference | batch=10, size=256x256: 262.2 ± 1.0 ms 9.2 - inference | batch=1, size=1024x1024: 440 ± 4 ms 9.3 - training | batch=10, size=224x224: 562 ± 4 ms 10/19. ResNet-SRGAN 10.1 - inference | batch=10, size=512x512: 223 ± 1 ms 10.2 - inference | batch=1, size=1536x1536: 199.2 ± 0.9 ms 10.3 - training | batch=5, size=512x512: 301 ± 1 ms 11/19. ResNet-DPED 11.1 - inference | batch=10, size=256x256: 230.4 ± 1.0 ms 11.2 - inference | batch=1, size=1024x1024: 390 ± 1 ms 11.3 - training | batch=15, size=128x128: 350 ± 1 ms 12/19. U-Net 12.1 - inference | batch=4, size=512x512: 459 ± 3 ms 12.2 - inference | batch=1, size=1024x1024: 454 ± 5 ms 12.3 - training | batch=4, size=256x256: 409 ± 2 ms 13/19. Nvidia-SPADE 13.1 - inference | batch=5, size=128x128: 188 ± 1 ms 13.2 - training | batch=1, size=128x128: 270.4 ± 0.9 ms 14/19. ICNet 14.1 - inference | batch=5, size=1024x1536: 192 ± 2 ms 14.2 - training | batch=10, size=1024x1536: 519 ± 6 ms 15/19. PSPNet 15.1 - inference | batch=5, size=720x720: 1001 ± 23 ms 15.2 - training | batch=1, size=512x512: 303 ± 2 ms 16/19. DeepLab 16.1 - inference | batch=2, size=512x512: 232 ± 3 ms 16.2 - training | batch=1, size=384x384: 234 ± 1 ms 17/19. Pixel-RNN 17.1 - inference | batch=50, size=64x64: 855 ± 14 ms 17.2 - training | batch=10, size=64x64: 3418 ± 45 ms 18/19. LSTM-Sentiment 18.1 - inference | batch=100, size=1024x300: 679 ± 13 ms 18.2 - training | batch=10, size=1024x300: 1550 ± 58 ms 19/19. GNMT-Translation 19.1 - inference | batch=1, size=1x20: 201 ± 4 ms Device Inference Score: 6439 Device Training Score: 7060 Device AI Score: 13499 For more information and results, please visit http://ai-benchmark.com/alpha
Результаты теста на облаке FloydHub (20.06.2020):
>> AI-Benchmark-v.0.1.2 >> Let the AI Games begin.. * TF Version: 2.1.0 * Platform: Linux-4.15.0-1032-aws-x86_64-with-debian-buster-sid * CPU: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz * CPU RAM: 60 GB * GPU/0: Tesla K80 * GPU RAM: 10.5 GB * CUDA Version: 10.0 * CUDA Build: V10.0.130 The benchmark is running... The tests might take up to 20 minutes Please don't interrupt the script 1/19. MobileNet-V2 1.1 - inference | batch=50, size=224x224: 136.5 ± 0.5 ms 1.2 - training | batch=50, size=224x224: 552 ± 7 ms 2/19. Inception-V3 2.1 - inference | batch=20, size=346x346: 222 ± 1 ms 2.2 - training | batch=20, size=346x346: 806 ± 2 ms 3/19. Inception-V4 3.1 - inference | batch=10, size=346x346: 238 ± 2 ms 3.2 - training | batch=10, size=346x346: 830 ± 2 ms 4/19. Inception-ResNet-V2 4.1 - inference | batch=10, size=346x346: 314 ± 1 ms 4.2 - training | batch=8, size=346x346: 907 ± 2 ms 5/19. ResNet-V2-50 5.1 - inference | batch=10, size=346x346: 156 ± 1 ms 5.2 - training | batch=10, size=346x346: 485 ± 1 ms 6/19. ResNet-V2-152 6.1 - inference | batch=10, size=256x256: 218.9 ± 0.5 ms 6.2 - training | batch=10, size=256x256: 737 ± 1 ms 7/19. VGG-16 7.1 - inference | batch=20, size=224x224: 312 ± 2 ms 7.2 - training | batch=2, size=224x224: 415 ± 1 ms 8/19. SRCNN 9-5-5 8.1 - inference | batch=10, size=512x512: 416 ± 4 ms 8.2 - inference | batch=1, size=1536x1536: 409 ± 2 ms 8.3 - training | batch=10, size=512x512: 1046 ± 4 ms 9/19. VGG-19 Super-Res 9.1 - inference | batch=10, size=256x256: 517.2 ± 0.7 ms 9.2 - inference | batch=1, size=1024x1024: 827 ± 1 ms 9.3 - training | batch=10, size=224x224: 1084 ± 3 ms 10/19. ResNet-SRGAN 10.1 - inference | batch=10, size=512x512: 415.1 ± 0.7 ms 10.2 - inference | batch=1, size=1536x1536: 393 ± 1 ms 10.3 - training | batch=5, size=512x512: 622 ± 4 ms 11/19. ResNet-DPED 11.1 - inference | batch=10, size=256x256: 475.8 ± 0.7 ms 11.2 - inference | batch=1, size=1024x1024: 924 ± 2 ms 11.3 - training | batch=15, size=128x128: 595.2 ± 0.4 ms 12/19. U-Net 12.1 - inference | batch=4, size=512x512: 968 ± 2 ms 12.2 - inference | batch=1, size=1024x1024: 982 ± 3 ms 12.3 - training | batch=4, size=256x256: 825 ± 1 ms 13/19. Nvidia-SPADE 13.1 - inference | batch=5, size=128x128: 450 ± 2 ms 13.2 - training | batch=1, size=128x128: 566 ± 1 ms 14/19. ICNet 14.1 - inference | batch=5, size=1024x1536: 436 ± 2 ms 14.2 - training | batch=10, size=1024x1536: 1161 ± 4 ms 15/19. PSPNet 15.1 - inference | batch=5, size=720x720: 1987 ± 4 ms 15.2 - training | batch=1, size=512x512: 635 ± 2 ms 16/19. DeepLab 16.1 - inference | batch=2, size=512x512: 494 ± 1 ms 16.2 - training | batch=1, size=384x384: 564 ± 1 ms 17/19. Pixel-RNN 17.1 - inference | batch=50, size=64x64: 1026 ± 11 ms 17.2 - training | batch=10, size=64x64: 2129 ± 15 ms 18/19. LSTM-Sentiment 18.1 - inference | batch=100, size=1024x300: 1436 ± 7 ms 18.2 - training | batch=10, size=1024x300: 2823 ± 13 ms 19/19. GNMT-Translation 19.1 - inference | batch=1, size=1x20: 318 ± 3 ms Device Inference Score: 3021 Device Training Score: 3653 Device AI Score: 6674 For more information and results, please visit http://ai-benchmark.com/alpha
Результаты теста на ПК с GPU GeForce RTX™ 2080 Ti GAMING OC 11G на материнке ASUS P8P67 REV 3.1. Отмечу, что слот на матери 2.0, а не 3.0, который поддерживает GPU:
1 x PCIe 2.0 x16
1 x PCIe 2.0 x16 (x4 mode, (Black)) *1
>> AI-Benchmark-v.0.1.2 >> Let the AI Games begin.. * TF Version: 2.1.0 * Platform: Windows-10-10.0.18362-SP0 * CPU: Intel(R) Core(TM) i7-2600K CPU @ 3.40GHz * CPU RAM: 16 GB * GPU/0: GeForce RTX 2080 Ti * GPU RAM: 8.5 GB * CUDA Version: 10.1 * CUDA Build: V10.1.105 The benchmark is running... The tests might take up to 20 minutes Please don't interrupt the script 1/19. MobileNet-V2 1.1 - inference | batch=50, size=224x224: 50.9 ▒ 1.1 ms 1.2 - training | batch=50, size=224x224: 204 ▒ 3 ms 2/19. Inception-V3 2.1 - inference | batch=20, size=346x346: 70.5 ▒ 6.2 ms 2.2 - training | batch=20, size=346x346: 176 ▒ 3 ms 3/19. Inception-V4 3.1 - inference | batch=10, size=346x346: 57.0 ▒ 3.2 ms 3.2 - training | batch=10, size=346x346: 176 ▒ 2 ms 4/19. Inception-ResNet-V2 4.1 - inference | batch=10, size=346x346: 69.1 ▒ 2.4 ms 4.2 - training | batch=8, size=346x346: 191 ▒ 2 ms 5/19. ResNet-V2-50 5.1 - inference | batch=10, size=346x346: 41.4 ▒ 2.7 ms 5.2 - training | batch=10, size=346x346: 109.9 ▒ 0.8 ms 6/19. ResNet-V2-152 6.1 - inference | batch=10, size=256x256: 49.0 ▒ 1.4 ms 6.2 - training | batch=10, size=256x256: 163 ▒ 6 ms 7/19. VGG-16 7.1 - inference | batch=20, size=224x224: 87.3 ▒ 3.3 ms 7.2 - training | batch=2, size=224x224: 144 ▒ 14 ms 8/19. SRCNN 9-5-5 8.1 - inference | batch=10, size=512x512: 84.3 ▒ 3.8 ms 8.2 - inference | batch=1, size=1536x1536: 72.7 ▒ 2.1 ms 8.3 - training | batch=10, size=512x512: 216 ▒ 5 ms 9/19. VGG-19 Super-Res 9.1 - inference | batch=10, size=256x256: 90.2 ▒ 1.3 ms 9.2 - inference | batch=1, size=1024x1024: 145 ▒ 4 ms 9.3 - training | batch=10, size=224x224: 253 ▒ 2 ms 10/19. ResNet-SRGAN 10.1 - inference | batch=10, size=512x512: 107 ▒ 6 ms 10.2 - inference | batch=1, size=1536x1536: 94.6 ▒ 2.0 ms 10.3 - training | batch=5, size=512x512: 149 ▒ 7 ms 11/19. ResNet-DPED 11.1 - inference | batch=10, size=256x256: 93.6 ▒ 1.0 ms 11.2 - inference | batch=1, size=1024x1024: 166 ▒ 1 ms 11.3 - training | batch=15, size=128x128: 161 ▒ 5 ms 12/19. U-Net 12.1 - inference | batch=4, size=512x512: 173 ▒ 2 ms 12.2 - inference | batch=1, size=1024x1024: 176 ▒ 8 ms 12.3 - training | batch=4, size=256x256: 183 ▒ 3 ms 13/19. Nvidia-SPADE 13.1 - inference | batch=5, size=128x128: 77.2 ▒ 1.3 ms 13.2 - training | batch=1, size=128x128: 127 ▒ 3 ms 14/19. ICNet 14.1 - inference | batch=5, size=1024x1536: 150 ▒ 1 ms 14.2 - training | batch=10, size=1024x1536: 442 ▒ 8 ms 15/19. PSPNet 15.1 - inference | batch=5, size=720x720: 312 ▒ 3 ms 15.2 - training | batch=1, size=512x512: 130 ▒ 2 ms 16/19. DeepLab 16.1 - inference | batch=2, size=512x512: 89.9 ▒ 0.8 ms 16.2 - training | batch=1, size=384x384: 107.8 ▒ 0.4 ms 17/19. Pixel-RNN 17.1 - inference | batch=50, size=64x64: 810 ▒ 4 ms 17.2 - training | batch=10, size=64x64: 2212 ▒ 39 ms 18/19. LSTM-Sentiment 18.1 - inference | batch=100, size=1024x300: 760 ▒ 18 ms 18.2 - training | batch=10, size=1024x300: 1352 ▒ 56 ms 19/19. GNMT-Translation 19.1 - inference | batch=1, size=1x20: 208 ▒ 4 ms Device Inference Score: 12060 Device Training Score: 13383 Device AI Score: 25443 For more information and results, please visit http://ai-benchmark.com/alpha
Полезные ссылки
- Сравнение недорогих GPU для задач обучения нейронных сетей.
- Железо Supermicro на которые ставятся Nvidia GPU.
- Тесты Nvidia по железу поддерживающему их GPU.
- Брошюра по железу Supermicro
- Конфигураторы железа Supermicro c поддержкой GPU Tesla.
- Бенчмарки различных GPU. Исходники.
- Тест от NVidia для сравнения GPU систем.
- Добротное сравнение GPU хостингов.
- https://github.com/minimaxir/deep-learning-cpu-gpu-benchmark
- https://github.com/mlpack/benchmarks
- https://hewlettpackard.github.io/dlcookbook-dlbs/#/
- https://dawn.cs.stanford.edu/benchmark/ — бенчмарки различных cloud GPU сервисов.