Задача генерации осмысленного текста сейчас широко используется, например, при создании чатботов (диалоговые системы вопрос-ответ), систем перевода (тот-же вопрос-ответ, но вопрос на одном языке, а ответ на другом). Рассмотрю структуру простого чатбота, взяв за основу лекции Сергея Кузина («Университете искусственного интеллекта«). В тексте рассматривается учебная задача для понимания.
Задача генерации осмысленного текста условно разбивается на две подзадачи. Сначала нейронной сети нужно выполнить анализ эталонного текста, а затем, поняв закономерности построения фраз сформировать новый текст, копируя манеру построения фраз текста на котором нейронка обучалась.
Примерная последовательность шагов для создания нейронной сети генерирующей текст следующая:
- Подготовка текстов для обучения — подобрать материал для обучения нейронной сети, т.е. найти подходящие по объему диалоги, тексты и пр.
- Предобработать (очистка от «мусора», токенизация) текст для обучения. Исключить из текстов «лишнюю» информацию, например, смайлы, «левые» вставки служебной информации (при экспорте переписки из WhatsApp он при исключении медиафайлов/фото/просоединенных файлов добавляет служебные строки) и т.п.
- Преобразовать в формат, пригодный для подачи на нейронную сеть (векторизация, числовые последовательности).
- Сформировать новый текст, используя некоторый алгоритм. Например, подходящую архитектуру нейронной сети.
- Преобразовать текст в машинно-читаемом коде в естественный язык.
При создании подобных алгоритмов разработчики сталкиваются с рядом проблем:
- Неоднозначность языка. Например, слова омонимы — слова звучат одинаково, но имеют разное значение, зависящее от контекста (горячий ключ, гаечный ключ, ключ от замка, ключ для решения проблемы и т.п.). Омографы — совпадают в написании, но различаются в произношении: хло́пок и хлопо́к, рой пчел — рой яму, замок — замо́к и т.п. Без контекста не понятно какое слово имелось в виду.
- Несимметричность языка — в разных языках по-разному кодируется смысл. Способ обработки пригодный для анализа одного языка не будет работать на другом. Например, различия во временах и пр.
- Обучающая база хорошо проработана для английского языка. Длядругих языков с базами ситуация выглядит не столь хорошо.
- Большая текстовая база — большие векторы текста, а следовательно, высокие требования к вычислительным ресурсам (память, GPU/TPU) и продолжительное обучение.
Для решения задач формирования текстов используются следующие подходы:
- Seq2Seq (Sequence-to-Sequence) — модель получает на вход некоторую последовательность слов (например, вопрос), анализирует её и, затем, на основе ранее созданнного обобщения (после тренировки), преобразует в новую последовательность.
- Word-2-Vec (Word-to-Vector) — предобученный embedding, который позволяет преобразовывать слова в тексте в некоторый вектор. В результате слова объединяются по некоторому признаку, например, группируются синонимы, географические названия и пр. Т.е. в новом пространстве векторов можно посмотреть расстояние между слова и сгруппировать их по некоторому критерию близости в этом пространстве.
- Doc-2-Vec (Document-to-Vector) — в пространство векторов происходит трансформация не слов, а документов. Напрмиер, дли некоторого исходного слова, скажем Франция, для одного документа будет объединение по географическому признаку (Испания, Италия). Для другого документа группировка будет по достопримечательностям относящимся к Франции. А по третьему — Франция будет сгруппирована в кластер объединяющий Европу, Америку, Азию.
В примере чатбота будет использована технология Sequence-2-sequence. Для её реализации будут использованы технологии:
- Embedding для векторизации.
- Рекуррентные нейронные сети (RNN), в частности, LSTM.
Sequence-to-Sequence (Seq2Seq)
Модель Seq2Seq состоит из двух основных блоков: encoder и decoder.
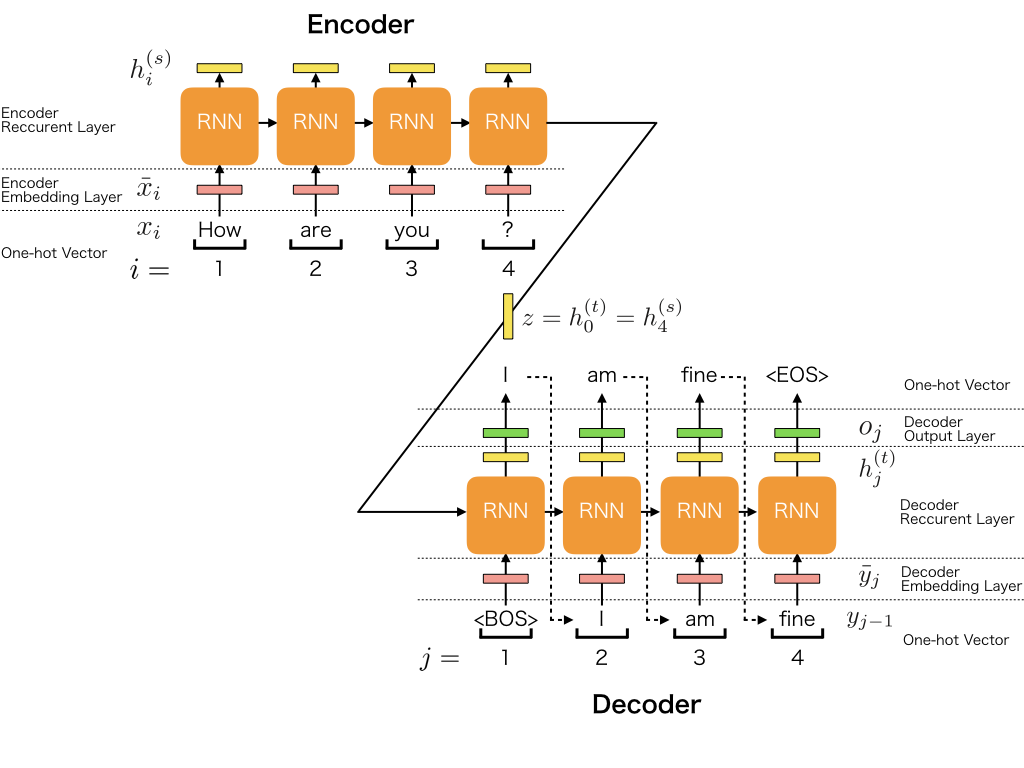
- На ячейки рекуррентной сети encoder подается исходная фраза разбитая по словам: «How are you?».
- Encoder обрабатывает её и на выходе получает некоторую закодированную последователность z.
- Decoder, помимо информации с выхода encoder-а, получает эталонный ответ на котором обучается: «I am fine».
- В процессе обучения декодер меняет свои веса таким образом, чтобы при получении исходного вопроса на вход, в идеале, выдать на выход эталонную фразу.
- При обучении фраза обрамляется стартовым с топовым тегом. В данном случае <BOS> — тег начала и <EOS> — тег окончания.
Для построения модели, которая сможет отвечать на вопросы условно будут работать две модели: тренировочная и рабочая. Сама нейронная сеть одна и та-же. Отличие только в способе использования.
Обучение seq2seq модели
Есть база вопросов и база ответов. Необходимо, чтобы были именно вопросы и ответы на них. Для нейронки должно быть понятно, что на текст вопроса дается определенный ответ.
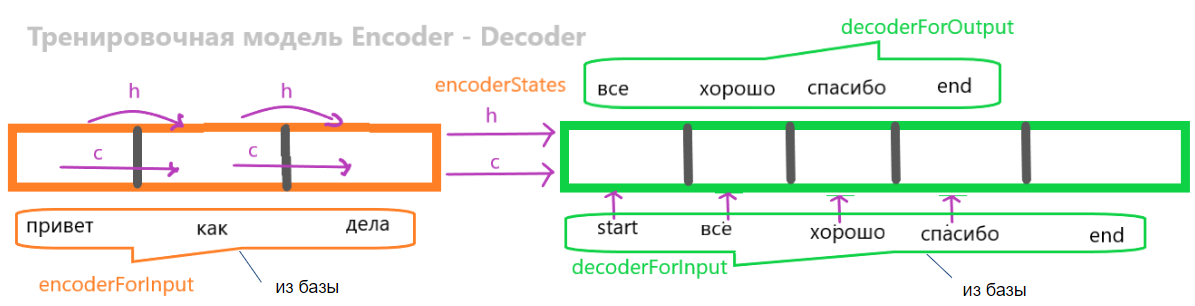
Для тренировочной модели последовательность обучения будет следующая:
- На вход encoder подаем вопрос. Например, «Привет, как дела?».
- Encoder его закодирует, используя слой embedding для конвертации слов в многомерный вектор и LSTM.
- На выходе LSTM encoder-а возвращается состояния h и c. В коде дальше будет понятно как попросить нейронку возвращать эти два параметра.
- Декодер также содержит embedding слой для векторизации ответа и LSTM.
- Для декодера эталонный ответ из обучающей выборки обрамим тегами открытия и закрытия: <start> и <end>. Теги могут быть любыми.
- Состояния h & c с encoder-а и эталонный ответ подается на вход decoder-а. Он на нём обучается и формрует ответ. Например, «все хорошо, спасибо <end>».
- Декодер в процессе обучения «поймет», что на тег начала фразы <start> на входе и некоторому состоянию с encoder нужно начать генерировать ответ.
- Кроме того декодер «осознает», что сгенерированную последовательность он должен завершить тегом <end>.

Обработка вопроса рабочей моделью будет следующая:
- Encoder в рабочей модели такой-же, как и в тренировочной модели. Разница лишь в том, что на его вход будет подаваться набранный пользователем вопрос, а не связка вопрос-ответ из обучающей базы.
- В рабочей модели используется ранее обученный декодер, но на вход ему будет подан только тег <start>.
- Декодер «понимает», что по приходу тега <start> нужно взять состояние с encoder и сгенерировать какое-то (одно) слово ответа.
- В идеале он сгенерирует первое слово в последовательности: «всё».
- Полученное слово «всё» подается на вход декодера вместе с состоянием полученным на предыдущем шаге на выходе декодера.
- Затем полученное слово «всё» вновь подается на вход декодера совместно с состоянием полученным на предыдущем шаге. На выходе декодер формрует слово <хорошо>.
- Новое слово вместе с состоянием в цикле вновь подается на вход декодера до тех пор, пока декодер не решит, что фраза завершена и вернет тег <end>.
Тренировочная модель
Работа encoder-а seq2seq
Рассмотрю по шагам работу encoder-а.
| На входе фраза очищенная от знаков пунктуации: | [Привет как дела] |
| Предложение подается на Tokenizer Keras для преобразования в последовательность чисел. На выходе 3 числа по количеству слов на входе. | [95 18 10] |
| Длина вопроса может быть разной, а размерность входа нейронки фиксированная. Нужно все вопросы привести к одной длине. Это делается добавлением 0-ей. Например, длина вопроса может быть не более 5 слов. Дополняем наши 3 цифры 2-мя нулями | [95 18 10 0 0] |
| На входе encoder-а первым стоит слой embedding. | |
| Слой embedding преобразует каждое слово в векторное пространство с заданной нами размерностью. Например, первым идет слово привет закодированное числом 95. Слой embedding преобразует это слово, например, в 200 мерное пространство. | |
| Слой embedding обучается также back propagation-ом, чтобы получить заданное нами n-мерное пространство из исходного слова. | |
| Полученная матрица будет подана на LSTM. |
| Encoder (слои + результаты) | ||
|---|---|---|
| Embedding | ||
| LSTM | ||
| На выходе LSTM — encoder state (ES): | h | c |
Работа decoder-а seq2seq
| Берем ответ на заданный вопрос из обучающей выборки. | [Спасибо все хорошо] |
| На первом шаге добавляем к этой последовательности теги начала <start> и конца <end> | [<start> Спасибо все хорошо <end>] |
| Предложение подается на Tokenizer Keras для преобразования в последовательность чисел. На выходе 5 чисел по количеству слов на входе. | [1 45 18 24 2] |
| Длина вопроса может быть разной. Вопросы приводим к одной длине добавлением 0-ей в последовательность слов. Например, максимальная длина ответа может быть равна 7 — добавляем в конец два 0-я. | [1 45 18 24 2 0 0] |
| Decoder (слои + результаты и доп. входы) | ||
|---|---|---|
| Embedding | ||
| С encoder-а ES на вход -> | LSTM | |
| Значения со всех ячеек LSTM | h | c |
| Dense c кол-ом нейронов = длине словаря и функцией активации — softmax |
Рабочая модель
В рабочей модели encoder такой-же, как в обучающей модели, поэтому отдельно не рассматриваю.
Работа decoder-а seq2seq
Архитектура decoder-а уже рассмотрена для учебной модели.
| 1 | Подаем стартовый тег на ранее обученный decoder | <start> |
| Используем Tokenizer Keras для преобразования последовательности в число. Получим одно число — 1. | [1] | |
| LSTM получает данные от embedding слоя и encoder-а (ES) | ||
| Первое значение возвращаемое Decoder-ом подается на dense слой | ||
| Значение выдаваемое на выходе dense обрабатывается argmax. Выбирается индекс для которого вероятность максимальная. | ||
| По полученному индексу из словаря выбирается соответствующее ему слово. Например, слово «спасибо». | ||
| Два других выхода LSTM назовем DS (decoder state) | ||
| 2 | На втором шаге цикла на вход архитектуры подается слово полученное на предыдущем шаге | спасибо |
| Используем Tokenizer Keras для преобразования последовательности в число. Получим одно число. | 45 | |
| Подаем нполученное слово на вход decoder-а. | ||
| Подаем на LSTM вместо ES предыдущее состояние decoder-а (DS). | ||
| На выходе после dense слоя и argmax получаем слово «всё» | всё | |
| …. | ||
| На выходе после dense слоя и argmax получаем закрывающий тег «<end>» по которому останавливаем цикл генерации фразы ответа. | <end> | |
| Цикл также будет остановлен по достижении некоторого установленного максимального количества итераций — максимальная длина фразы ответа. |
Естественно, при обучении такой модели слова могут быть только те, которые содержались в словаре. Если модель в ответе встретит неизвестное слово — она «упадет».
В идеале после тренировки модели она на заданный вопрос должна давать адекватный ответ.
Импорт текста чата из WhatsApp на Python
В качестве примера буду использовать общение экспортированное из чата WhatsApp в файл communic.txt.
В данном случае импорт не полноценный. Пока я изучал что накидал WhatsApp в файл мне было проще в текстовом редакторе сделать замену ников собеседников на Person_1 и Person_2 и убрать колонку с датой. Впрочем, вписать такую преодобработку в код недолго.
В выгрузке чата удаляются наиболее часто используемые смайлы и выбрасываются проблемы, табуляции и пр. в начале и конце фразы:
phrase = ''.join(i for i in phrase if not i in smiles).strip() #Удаляем smiles из фразы
Кроме того пропускаются все служебные вставки вроде «<Media omitted>».
Проверяется, что фразы — это текстовые данные:
if type(phrase) != str: #Пропускаем строки с нетекстовыми данными continue
#@title WhatsApp chat parser { display-mode: "form" }
import re
questions = list() # здесь будет список вопросов
answers = list() # здесь будет список ответов
max_question_len = 500
max_answer_len = 500
smiles = ['?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?',
'?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '?', '☺', '?',
'?', '?', '?', '?', '?', '?', '☹', '?', '?', '?', '?', '?', '?', '?', '?', '?',
'?', '?', '?', '?', '?', '?', '?', '?', '☀', '❄', '?', '?', '?', '?', '?', '?', '?']
corpus = open('communic.txt', 'r') # открываем файл с диалогами в режиме чтения
lastPerson = ''
for line in corpus.readlines():
line = line.strip()
phrase = line[len('Person_1: ') : len(line)]
phrase = ''.join(i for i in phrase if not i in smiles).strip() #Удаляем smiles из фразы
phrase = re.sub(r'http\S+', '', phrase) #Удаляем ссылку из текста
if (len(phrase) == 1) and (phrase in smiles): #Убираем смайлы, если строка только из смайлов.
continue
if ("<Media omitted>" in phrase) or ("This message was deleted" in phrase): #Skip omitted media
continue
if type(phrase) != str: #Пропускаем строки с нетекстовыми данными
continue
if line.startswith('Person_2:'):
if (lastPerson == 'Person_2'): #Если автор следующей строки тот-же человек
if (len(questions[-1]) + len(phrase) < max_question_len):
questions[-1] += " " + phrase #Дописываем в конец предыдущей фразы новую фразу
else:
questions.append(phrase)
lastPerson = 'Person_2'
if line.startswith('Person_1:'):
if (lastPerson == 'Person_1'): #Если автор следующей строки тот-же человек
if (len(answers[-1]) + len(phrase) < max_answer_len): #Проверяем, что фраза не длиннее заданной
answers[-1] += " " + phrase #Дописываем в конец предыдущей фразы новую фразу
else:
if (len(answers) > 0):
answers[-1] += " <END>" #Добавляем теги-метки для конца ответов
answers.append('<START> ' + phrase) #Добавляем теги-метки для начала ответов
lastPerson = 'Person_1'
questions = questions[:2500]
answers = answers[:2500]Кроме того фразы от одного человека на разных строчках объединяются и к фразам ответов (в данном случае отвечающим выбран «Person_2») добавляются теги разметки фразы: «<START>» и «END>».
Реплики Person_2 заносятся в массив questions, а Person_2 — в answers.
Токенизация текста
Используем Keras Tokenizer. С ним возникла странная проблема на версии из Colab. По идее при передаче аргумента num_words=vocabularySize, где указан размер словаря, токенизатор должен был бы ограничить количество слов заданным, но он это упорно не делал.
#@title Подключаем керасовский токенизатор и собираем словарь индексов { display-mode: "form" }
#vocabularySize = 1000 #30000
tokenizer = Tokenizer(num_words=None) #num_words=vocabularySize, filters='!–"—#$%&()*+,-./:;=?@[\\]^_`{|}~\t\n\r«»'
tokenizer.fit_on_texts(questions + answers) # загружаем в токенизатор список вопросов-ответов для сборки словаря частотности
vocabularyItems = list(tokenizer.word_index.items()) # список с cодержимым словаря
vocabularySize = len(vocabularyItems)+1 # размер словаря
print( 'Фрагмент словаря : {}'.format(vocabularyItems[:100]))
print( 'Размер словаря : {}'.format(vocabularySize))В результате, чтобы при перекодировании в OHE не падал Colab из-за нехватки памяти (даже при использовании TPU) я ограничил количество входных фраз, чтобы сократить размер словаря таким образом. Это сработало, хотя это неправильный подход. Можно было урезать количество слов в словаре уже после обработки Tokenizer-ом.
Чтобы код не падал, если пользователь ввел слово отсутствущее в словаре, нужно добавить в Tokenizer аргумент oov_token = «unknown». oov — Out Of Vocab (OOV) token.
Далее простейший код конвертации исходных фраз в индексы. Как упоминалось ранее, чтобы подать вопросы на сеть у которой фиксированный размер входа вопросы с произвольным длином слов, нужно дополнить массив индексов 0-ми.
Берем максимальное количество слов во фразе maxLenQuestions и во всех фразах с меньшим количеством слов дополняем индексы 0-ми используя pad_sequences. padding=’post’ говорит pad_sequences, чтобы нули добавлялись в конце фразы.
#@title Подготавливаем данные для нейронной сети (вопросы или ответы) { display-mode: "form" }
def prepareDataForNN(phrases, isQuestion = True):
tokenizedPhrases = tokenizer.texts_to_sequences(phrases) # разбиваем текст вопросов/ответов на последовательности индексов
maxLenPhrases = max([ len(x) for x in tokenizedPhrases]) # уточняем длину самого большого вопроса.ответа
# Делаем последовательности одной длины, заполняя нулями более короткие вопросы
paddedPhrases = pad_sequences(tokenizedPhrases, maxlen=maxLenPhrases, padding='post')
# Предподготавливаем данные для входа в сеть
encoded = np.array(paddedPhrases) # переводим в numpy массив
phraseType = "вопрос"
if not isQuestion:
phraseType = "ответ"
print('Пример оригинального ' + phraseType + 'а на вход : {}'.format(phrases[100]))
print('Пример кодированного ' + phraseType + 'а на вход : {}'.format(encoded[100]))
print('Размеры закодированного массива ' + phraseType + 'ов на вход : {}'.format(encoded.shape))
print('Установленная длина ' + phraseType + 'ов на вход : {}'.format(maxLenPhrases))
return encoded, maxLenPhrasesАналогичный код для ответов, но вместо questions используется answers.
#@title Устанавливаем закодированные входные данные(вопросы) { display-mode: "form" }
encoderForInput, maxLenQuestions = prepareDataForNN(questions, True)Пример оригинального вопроса на вход : Мысли сходятся) Тут надо просто уметь выйти из состояния боли
Пример кодированного вопроса на вход : [ 335 2320 134 28 33 916 1277 38 1639 1062 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
Размеры закодированного массива вопросов на вход : (2500, 80)
Установленная длина вопросов на вход : 80#@title Устанавливаем раскодированные входные данные (ответы) { display-mode: "form" }
decoderForInput, maxLenAnswers = prepareDataForNN(answers, False)Пример оригинального ответа на вход: <START> Я тоже не думал, что у меня так выйдет. :-) <END>
Пример раскодированного ответа на вход : [ 2 4 29 3 202 7 9 15 24 1208 1 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0]
Размеры раскодированного массива ответов на вход : (2500, 128)
Установленная длина ответов на вход : 128Получаем 2500 ответов с максимальной длиной 128. Длина очень большая, что нехорошо при генерации текста.
В качестве правильного ответа на выход нейронки будет подан One Hot Encoding (OHE) полученный из массива ответов. Это y_train — то, с чем будет сравниваться выход декодера.
Здесь есть одна большая проблема. При конвертации в OHE каждое число в исходныом векторе длины 128 развернется в вектор из 0 и 1-ц с длиной равной длины словаря, где на всех позициях будут 0, кроме одной позиции равной числу, где будет стоять 1-ца. Получится большая разреженная матрица, которая влегкую опустошит всю выделенную память, после чего Colab упадет. 🙁
Тренировку модели нужно выполнять на TPU, а не на GPU. В этом случае ресурсов выделяется больше и разреженная матрица нормально строится.
#@title Раскодированные выходные данные(ответы) { display-mode: "form" }
print("Answers:", len(answers))
tokenizedAnswers = tokenizer.texts_to_sequences(answers) # разбиваем текст ответов на последовательности индексов
print("tokenizedAnswers:", len(tokenizedAnswers))
for i in range(len(tokenizedAnswers)) : # для разбитых на последовательности ответов
tokenizedAnswers[i] = tokenizedAnswers[i][1:] # избавляемся от тега <START>
# Делаем последовательности одной длины, заполняя нулями более короткие ответы
paddedAnswers = pad_sequences(tokenizedAnswers, maxlen=maxLenAnswers , padding='post')
print("paddedAnswers:", len(paddedAnswers))
print("vocabularySize:", vocabularySize)
oneHotAnswers = utils.to_categorical(paddedAnswers, vocabularySize) # переводим в one hot vector
decoderForOutput = np.array(oneHotAnswers) # и сохраняем в виде массива numpyЧтобы как-то переварить фразы нужно уменьшать размер словаря. Как вариант, можно попробовать использовать в качестве loss вместо ‘categorical_crossentropy’ собрата работающего с матрицами без конвертации в в OHE: ‘sparse_categorical_crossentropy’. О использовании ‘sparse_categorical_crossentopy’ в продолжении статьи.
Архитектура нейронной сеть
Первый слой — слой encoder-а. В параметрах embedding стоит mask_zero=True, чтобы исключать нулевые значения. Так сеть будет обучаться быстрее. Размерность пространства embedding = 200. Т.е. каждое слово будет развернуто в это пространство.
#@title Первый входной слой, кодер, выходной слой { display-mode: "form" }
encoderInputs = Input(shape=(None , ), name = "EncoderForInput") # размеры на входе сетки (здесь будет encoderForInput)
# Эти данные проходят через слой Embedding (длина словаря, размерность)
encoderEmbedding = Embedding(vocabularySize, 200 , mask_zero=True, name = "Encoder_Embedding") (encoderInputs)
# Затем выход с Embedding пойдёт в LSTM слой, на выходе у которого будет два вектора состояния - state_h , state_c
# Вектора состояния - state_h , state_c зададутся в LSTM слое декодера в блоке ниже
encoderOutputs, state_h , state_c = LSTM(200, return_state=True, name = "Encoder_LSTM")(encoderEmbedding)
encoderStates = [state_h, state_c]Размерность encoderInput равна размеру batchsize (None) на максимальную длину вопроса, равную 80. Вместо None в аргументе Input(shape=(None , )) можно было поставить maxLenQuestions.
В параметрах LSTM слоя передается return_state=True, чтобы LSTM слой помимо выхода возвращал ещё состояния: h и c. Они объединяются в encoderStates и подаются на вход LSTM декодера.
Важный момент при создании слоя LSTM. Помимо return_state=True, который говорит LSTM слою вернуть все состояния, добавляется ещё параметр return_sequences=True. Этот параметр говорит LSTM вернуть значения с каждой из LSTM ячеек, а не только с последней.
На вход LSTM слоя декодера помимо значений с Embedding слоя подается ещё начальное состояние LSTM, полученное от encoder-а: initial_state=encoderStates.
Размерность decoderInput равна размеру batchsize (None) на максимальную длину вопроса, равную 128. Вместо None в аргументе Input(shape=(None , )) можно было поставить maxLenAnswers.
#@title Второй входной слой, декодер, выходной слой { display-mode: "form" }
decoderInputs = Input(shape=(None, ), name = "DecoderForInput") # размеры на входе сетки (здесь будет decoderForInput)
# Эти данные проходят через слой Embedding (длина словаря, размерность)
# mask_zero=True - игнорировать нулевые padding при передаче в LSTM. Предотвратит вывод ответа типа: "У меня все хорошо PAD PAD PAD PAD PAD PAD.."
decoderEmbedding = Embedding(vocabularySize, 200, mask_zero=True, name = "Decoder_Embedding") (decoderInputs)
# Затем выход с Embedding пойдёт в LSTM слой, которому передаются вектора состояния - state_h , state_c
decoderLSTM = LSTM(200, return_state=True, return_sequences=True, name = "Decoder_LSTM")
decoderOutputs , _ , _ = decoderLSTM (decoderEmbedding, initial_state=encoderStates)
# И от LSTM'а сигнал decoderOutputs пропускаем через полносвязный слой с софтмаксом на выходе
decoderDense = Dense(vocabularySize, activation='softmax')
output = decoderDense (decoderOutputs)#@title Собираем тренировочную модель нейросети { display-mode: "form" }
model = Model([encoderInputs, decoderInputs], output)
model.compile(optimizer=RMSprop(), loss='categorical_crossentropy')
print(model.summary()) # выведем на экран информацию о построенной модели нейросети
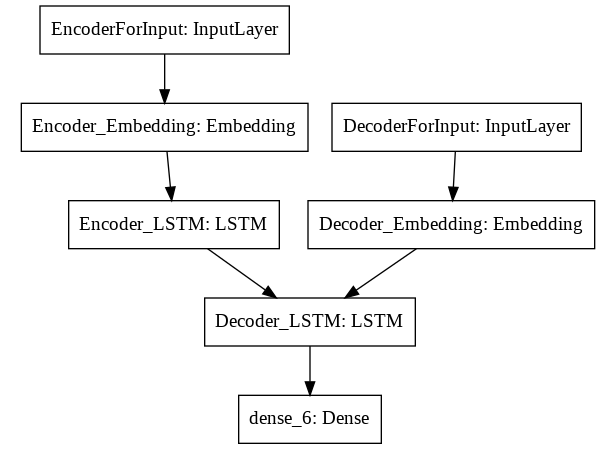
plot_model(model, to_file='model.png') # и построим график для визуализации слоев и связей между нимиРезультирующая модель в разбивке по слоям будет такой:

Первый аргмент «None» — размер batch. На выходе embedding слоя набор матриц с размерностью 80х200. Т.е. каждый вопрос представленный в виде 80 слов, часть из которых 0 будет представлен в виде вектора с размерностью 200. Аналогично для выходного слоя.
На выходе LSTM три выхода размерности 200 (три раза (None, 200)). Два последних элемента — это состояния h и c, которые будут записаны в encoderStates и переданы на вход LSTM декодера.
LSTM декодера вернет также три значения, но нам нужно первое. Оно будет подано на Dense слой, который вернет на выходе матрицу 128 х 10978. Эта размерность совпадает с той, что будет получена на выходе в «Раскодированные выходные данные(ответы)» после OHE. Таким образом эти данные можно сравнивать, чтобы производить обучение сети.
Визуализация соединений входов и выходов каждого слоя plot_model(model, to_file=’model.png’)
Далее модель обучается:
# Запустим обучение и сохраним модель
model.fit([encoderForInput , decoderForInput], decoderForOutput, batch_size=50, epochs=50,
callbacks=[MyCallback(), reduce_lr]) Поскольку Colab периодически дисконнектится, очищая все данные на диске, я написал callback, который через определенные промежутки времени сохраняет наилучшие веса на ftp:
#@title Класс callback-а для сохранения весов нейронной сети { display-mode: "form" }
import keras
import sys
import time
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
class MyCallback(keras.callbacks.Callback):
def __init__(self):
super().__init__()
self.best_criterion = sys.float_info.max
self.counter = 0
self.interval = 5 #Интервал для сохранения
self.best_weights_filename = "best_weights_chatbot_150_epochs.h5"
print(self.best_weights_filename)
def on_epoch_begin(self, epoch, logs={}):
self.epoch_time_start = time.time()
def on_epoch_end(self, epoch, logs=None):
#'loss', 'val_loss', 'val_mean_squared_error', 'mean_squared_error'
criterion = 'loss'
if (logs[criterion] < self.best_criterion):
print("\r\nНайдено лучшее значение " + criterion + ". Было", self.best_criterion, "Стало:", logs[criterion], "Сохраняю файл весов. Итерация:", self.counter, "\r\n")
self.model.save_weights(self.best_weights_filename) #"best_weights.h5"
if ((self.counter % self.interval) == 0):
print("Сохраняю файл весов на ftp.")
!curl -ss -T $self.best_weights_filename ftp://[login]:[password]@vh46.timeweb.ru
self.best_criterion = logs[criterion] #Сохраняем значение лучшего результата
self.counter += 1
#early_stopping = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10)
reduce_lr = ReduceLROnPlateau(monitor='loss', factor=0.2, verbose=1, patience=5, min_lr=1e-12)Каждая эпоха на Colab обучается примерно 2 минуты. Я запускал суммарно обучение примерно на 200 эпохах, сохраняя данные и восстанавливая модель c ftp при каждом запуске обучения.
Подготовка и запуск рабочей нейросети
После обучения тренировочной модели нужно создать рабочую модель. Это та мудреная структура, которая при подаче на вход состояния с encoder-а и стартового тега <start> должна сгенерировать выходное словое и новое состояние, которые должны последовательно поступать на ячейки LSTM слоя.
На модель приходит вопрос encoderInputs и на выходе возвращается состояние encoderStates.
#@title Создаем рабочую модель для вывода ответов на запросы пользователя { display-mode: "form" }
def makeInferenceModels():
# Определим модель кодера, на входе далее будут закодированные вопросы(encoderForInputs), на выходе состояния state_h, state_c
encoderModel = Model(encoderInputs, encoderStates)
decoderStateInput_h = Input(shape=(200 ,), name = 'decoderStateInput_h') # обозначим размерность для входного слоя с состоянием state_h
decoderStateInput_c = Input(shape=(200 ,), name = 'decoderStateInput_c') # обозначим размерность для входного слоя с состоянием state_c
decoderStatesInputs = [decoderStateInput_h, decoderStateInput_c] # возьмем оба inputs вместе и запишем в decoderStatesInputs
# Берём ответы, прошедшие через эмбединг, вместе с состояниями и подаём LSTM cлою
decoderOutputs, state_h, state_c = decoderLSTM(decoderEmbedding, initial_state=decoderStatesInputs)
decoderStates = [state_h, state_c] # LSTM даст нам новые состояния
decoderOutputs = decoderDense(decoderOutputs) # и ответы, которые мы пропустим через полносвязный слой с софтмаксом
# Определим модель декодера, на входе далее будут раскодированные ответы (decoderForInputs) и состояния
# на выходе предсказываемый ответ и новые состояния
decoderModel = Model([decoderInputs] + decoderStatesInputs, [decoderOutputs] + decoderStates)
print(decoderModel.summary()) # выведем на экран информацию о построенной модели нейросети
plot_model(decoderModel, to_file='decoderModel.png') # и построим график для визуализации слоев и связей между ними
return encoderModel , decoderModelВыведем полученную модель декодера:
from IPython.display import SVG
from keras.utils import model_to_dot
import matplotlib.pyplot as plt
import matplotlib.image as img
encModel , decModel = makeInferenceModels() # запускаем функцию для построения модели кодера и декодера
# reading png image file
im = img.imread('decoderModel.png')
# show image
plt.figure(figsize=(20,10))
plt.axis('off')
plt.imshow(im)

По изображению модели видно, что запись в коде:
decoderModel = Model([decoderInputs] + decoderStatesInputs, [decoderOutputs] + decoderStates)
[decoderInputs] + decoderStatesInputs — обозначает добавление к входу Decoder_Embedding ещё двух: decoderStateInput_h и decoderStateInput_c.
То, что вводит пользователь должно быть преобразовано в последовательность индексов с помощью функции:
#@title Функция преобразующая вопрос пользователя в последовательность индексов { display-mode: "form" }
def strToTokens(sentence: str): # функция принимает строку на вход (предложение с вопросом)
words = sentence.lower().split() # приводит предложение к нижнему регистру и разбирает на слова
tokensList = list() # здесь будет последовательность токенов/индексов
for word in words: # для каждого слова в предложении
tokensList.append(tokenizer.word_index[word]) # определяем токенизатором индекс и добавляем в список
# Функция вернёт вопрос в виде последовательности индексов, ограниченной длиной самого длинного вопроса из нашей базы вопросов
return pad_sequences([tokensList], maxlen=maxLenQuestions , padding='post')Ну и код, который принимает на вход то, что ввел пользователь и преобразует в ответ нейронной сети:
#@title Устанавливаем окончательные настройки и запускаем модель { display-mode: "form" }
encModel , decModel = makeInferenceModels() # запускаем функцию для построения модели кодера и декодера
for _ in range(6): # задаем количество вопросов, и на каждой итерации в этом диапазоне:
# Получаем значения состояний, которые определит кодер в соответствии с заданным вопросом
statesValues = encModel.predict(strToTokens(input( 'Задайте вопрос : ' )))
# Создаём пустой массив размером (1, 1)
emptyTargetSeq = np.zeros((1, 1))
emptyTargetSeq[0, 0] = tokenizer.word_index['start'] # положим в пустую последовательность начальное слово 'start' в виде индекса
stopCondition = False # зададим условие, при срабатывании которого, прекратится генерация очередного слова
decodedTranslation = '' # здесь будет собираться генерируемый ответ
while not stopCondition : # пока не сработало стоп-условие
# В модель декодера подадим пустую последовательность со словом 'start' и состояния предсказанные кодером по заданному вопросу.
# декодер заменит слово 'start' предсказанным сгенерированным словом и обновит состояния
decOutputs , h , c = decModel.predict([emptyTargetSeq] + statesValues)
#argmax пробежит по вектору decOutputs, найдет макс.значение, и вернёт номер индекса под которым оно лежит в массиве
sampledWordIndex = np.argmax( decOutputs[0, 0, :]) # argmax возьмем от оси, в которой x элементов. Получили индекс предсказанного слова.
sampledWord = None # создаем переменную, в которую положим слово, преобразованное на естественный язык
for word , index in tokenizer.word_index.items():
if sampledWordIndex == index: # если индекс выбранного слова соответствует какому-то индексу из словаря
decodedTranslation += ' {}'.format(word) # слово, идущее под этим индексом в словаре, добавляется в итоговый ответ
sampledWord = word # выбранное слово фиксируем в переменную sampledWord
# Если выбранным словом оказывается 'end' либо если сгенерированный ответ превышает заданную максимальную длину ответа
if sampledWord == 'end' or len(decodedTranslation.split()) > maxLenAnswers:
stopCondition = True # то срабатывает стоп-условие и прекращаем генерацию
emptyTargetSeq = np.zeros((1, 1)) # создаем пустой массив
emptyTargetSeq[0, 0] = sampledWordIndex # заносим туда индекс выбранного слова
statesValues = [h, c] # и состояния, обновленные декодером
# и продолжаем цикл с обновленными параметрами
print(decodedTranslation) # выводим ответ сгенерированный декодеромСначала функцией makeInferenceModel получаем модель encoder-a и decoder-а. С помощью функции:
statesValues = encModel.predict(strToTokens(input( 'Задайте вопрос : ' )))
преобразуем фразу пользователя в состояние на выходе encoder-а.
На первом шаге в рабочую модель подается тег start, чтобы инициировать работу декодера и состояние полученное с выхода encoder-а после обработки фразы пользователя.
decOutputs , h , c = decModel.predict([emptyTargetSeq] + statesValues)
Далее с помощью argmax из decOutputs выбирается индекс слова, для которого нейронная сеть предсказала наибольшую вероятность появления в ответе.
sampledWordIndex = np.argmax( decOutputs[0, 0, :]) # Получили индекс предсказанного слова.
Из словаря по индексу находится слово и добавляется в переменную ответа для формирования фразы.
Если нейронка предсказала тег end, то считаем, что фраза сформирована и нужно остановить работу декодера.
Индекс предсказанного нейронкой слова полученного на выходе декодера помещается в переменную emptyTargetSeq. Состояния помещаются в переменную: statesValues = [h, c] и тоже передаются на декодер на очередной итерации цикла.
Выводы
Я пробовал подавать на эту модель данные взятые из переписки в WhatsApp. Реплики одного участника считал за вопрос, а другого — за ответ. Результат неважный для такой задачи. Для обучения систем Вопрос-Ответ мессенджеры и соц. сети не подходят, поскольку:
- Контекст, нередко, находится за рамками диалога.
- Много сленга, смайлов, медиа.
- Обсждение медиафайлов (фото, видео) проблематично подать на нейронку такого типа.
- Нет непосредственной связи между вопросами и ответами.
Для таких задач лучше использовать данные с площадок вроде «Ответы mail.ru» или Reddit. В этом случае контекст максимальный и есть четкая связь между вопросами и ответами.
Для решения такаго рода задач чаще используется архитектура «Трансформеры«. Рекуррентные сети им пока проиграли.
Итак:
- После обучения на базах с нормальными вопросами и ответами без какого-то размазанного контекста, результат получается неплохой. Нейронка выдает вполне интересные ответы.
- После обучения на данных выгруженных из чата WhatsApp результат отвратительный. Нейронка выдает чушь.
- При такой архитектуре сети есть проблемы с памятью для разреженной матрицы OHE. По идее надо подумать как использовать loss = sparse_categorical_crossentropy. Подробнее в статье.
- LSTM обучаются долго, Colab вылетает часто, поэтому без сохранения весов нельзя.