В предыдущей статье мы разбирались с обычными GAN-ами. В статье подробно рассмотрено, как работает нейронная сеть такого типа. В этой — разберу, как работают генеративные сети с условием. В качестве основы для кода буду использовать статью, но базу цифр, а не одежды. Colab с экспериментами здесь.
В статье приведено сравнение различных архитектур генеративных сетей с условиями. Архитектуры нейронных сетей, формирующие результат по заданным критериям: CGAN (Conditional Generative Adversarial Networks), ACGAN (Auxiliary Classifier Generative Adversarial Networks), infoGAN, EBGAN (Energy-Based Generative Adversarial Network).

- c — это класс, например, в случае с MNIST — это цифры от 0 до 9.
- z — шум, подаваемый на генератор.
- x — реальные данные, подаваемые для обучения дискриминатора.
- G — генератор (творец).
- D — дискиминатор (критик).
В случае с MNIST цель GAN-ов с условием — получать не просто какую-то цифру при подаче шума на генератор, а конкретную. Например, в случае с MNIST задали 9 в качестве класса и получили набор рукописных цифр 9 с генератора.
Код CGAN на Keras
Код снабжен большим количеством комментариев, взятых по аналогии из курса «Нейронные сети на Python«, читаемого Дмитрием Романовым в «Университете искусственного интеллекта«. Значимых для понимания кода комментариев немного, я на них акцентирую внимание отдельно.
Генератор
Метод генератора в классе СGAN-а практически не отличается от ранее рассмотренного кода GAN:
def build_generator(self): #Метод для создания генератора
noise_shape = (self.latent_dim,)
model = Sequential() # Инициализируем модель generator
model.add(Dense(256, input_shape=noise_shape, name = "Generator_In")) # Добавляем Dense-слой на 256 нейронов (размерность входных данных = latent_dim)
model.add(LeakyReLU(alpha=0.2)) # Добавляем слой активационной функции с параметром 0.2
model.add(BatchNormalization(momentum=0.8)) # Добавляем слой BatchNormalization (momentum - параметр расчета скользящего среднего и дисперсии)
model.add(Dense(512)) # Добавляем Dense-слой на 512 нейронов
model.add(LeakyReLU(alpha=0.2)) # Добавляем слой активационной функции с параметром 0.2
model.add(BatchNormalization(momentum=0.8)) # Добавляем слой BatchNormalization (momentum - параметр расчета скользящего среднего и дисперсии)
model.add(Dense(1024)) # Добавляем Dense-слой на 1024 нейронов
model.add(LeakyReLU(alpha=0.2)) # Добавляем слой активационной функции с параметром 0.2
model.add(BatchNormalization(momentum=0.8)) # Добавляем слой BatchNormalization (momentum - параметр расчета скользящего среднего и дисперсии)
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape, name = "Generator_Out"))
model.name = "Generator"
model.summary()
noise = Input(shape=noise_shape) # Создаем слой Input (Записываем входные данные рамерностью latent_dim в noise)
И далее кусок кода, который был адаптирован от GAN для CGAN:
label = Input(shape=(1,), dtype='int32') # Создаем слой Input (Записываем входные данные рамерностью (1) в label)
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label)) # Создаем слой Flatten() от слоя Embedding с входными параметрами num_classes и latent_dim
model_input = multiply([noise, label_embedding]) # Объединяем слои noise и label_embedding с помощью multiply
img = model(model_input) # Записываем в переменную img значение, возвращаемое generator'ом с входным параметром noise
return Model(inputs = [noise, label], outputs = img) # Возвращаем модель generator-а (входные данные: noise, выходные данные: img)Разница с GAN в подмешивании в генераторе ко входному вектору шума вектора с значениями от 0 до 9. Подмешивание производится функцией multiply([noise, label_embedding]). Исходные цифры 0..9 конвертируются для подмешивания с помощью функции Keras Embedding() для входного вектора шума с размерностью latent_dim.
В дальнейшем при тренировке генератора мы передадим ему метки в той же последовательности, какая будет использоваться при тренировке дискриминатора.
Дискриминатор
Дискриминатор в C-GAN устроен практически так же, как в GAN. Разница лишь в финальной части, где к изображению добавляется метка.
def build_discriminator(self, img_shape): # Функция создания дискриминатора
model = Sequential() # Инициализируем модель discriminator
model.add(Flatten(input_shape=img_shape, name = "Discriminator_In")) # Создаем слой Flatten (размерность входных данных = (img_rows, img_cols, channels), размерность выходных данных = img_rows * img_cols * channels )
model.add(Dense(512)) # Добавляем Dense-слой на 512 нейронов
model.add(LeakyReLU(alpha=0.2)) # Добавляем слой активационной функции с параметром 0.2
model.add(Dense(256)) # Добавляем Dense-слой на 256 нейронов
model.add(LeakyReLU(alpha=0.2)) # Добавляем слой активационной функции с параметром 0.2
model.add(Dense(1, activation='sigmoid', name = "Discriminator_Out")) # Добавляем Dense-слой c 1 нейроном с активационной функцией sigmoid, поскольку нам нужно категорировать входноые изображения на два класса 1 - из тестовой выборки и 0 - сформирован генератором.
model.name = "Discriminator"
model.summary()
img = Input(shape=img_shape) # Создаем слой Input (записываем входные данные размерностью (img_rows, img_cols, channels) в img)
label = Input(shape=(1,), dtype='int32') # Создаем слой Input (Записываем входные данные рамерностью (1) в label)На вход дискриминатора подаются изображения с генератора и из файлов, а также метка, связанная с этим изображением. Дискриминатор обучается определять изображения, когда к нему через Embedding() подмешана метка от 0 до 9.
label_embedding = Flatten()(Embedding(self.num_classes, np.prod(img_shape))(label)) # Создаем слой Flatten() от слоя Embedding с входными параметрами num_classes и (img_rows * img_cols * channels)
flat_img = Flatten()(img) # Создаем слой Flatten() от слоя img
model_input = multiply([flat_img, label_embedding]) # Объединяем слои flat_img и label_embedding с помощью multiply
validity = model(model_input) # Записываем в переменную validity значение, возвращаемое discriminator'ом с входным параметром model_input
return Model(inputs = [img, label], outputs = validity) # Создаем модель discriminator (входные данные: img, выходные данные: validity)Тренировка C-GAN модели
def train(self, epochs, batch_size=128, save_interval=1000, save_images = False):
# Load the dataset
(X_train, y_train), (_, _) = mnist.load_data()
# Rescale -1 to 1
X_train = (X_train.astype(np.float32) - 127.5) / 127.5 # Масштабируем значение в диапазон от -1 до 1, поскоьлку активационная функция tanh, у которого значения лежат от -1 до +1
X_train = np.expand_dims(X_train, axis = 3) # Добавляем третью размерность для X_train ((28,28) => (28,28,1))
y_train = y_train.reshape(-1, 1) # решейпим y_train его в размерность (60000, 1)
valid = np.ones((batch_size, 1)) # Создаем массив единиц длинной batch_size
fake = np.zeros((batch_size, 1)) # Создаем массив нулей длинной batch_size
for epoch in range(epochs):
# ---Train Discriminator---
idx = np.random.randint(0, X_train.shape[0], batch_size) # Выбираем случайным образом batch_size картинок из исходной обучающей выбрки для тренировки дискриминатора
imgs, labels = X_train[idx], y_train[idx] # В переменную imgs записываем значение из X_train с индексами из idx, в переменную labels записываем значения из y_train с индексами из idx
noise = np.random.normal(0, 1, (batch_size, self.latent_dim)) # Формируем массив размерностью (batch_size, self.latent_dim) из нормально распределенных значений
gen_imgs = self.generator.predict([noise, labels]) # Формируем массив изображений с помощью входной переменной generator
self.discriminator.trainable = True
d_loss_real = self.discriminator.train_on_batch([imgs, labels], valid) # Ошибка дискриминатора, обученного на реальных картинках. Передаем в функцию train_on_batch реальные изображения (imgs), метки (labels) и массив единиц (valid).
d_loss_fake = self.discriminator.train_on_batch([gen_imgs, labels], fake) # Ошибка дискриминатора, обученного на сгенерированных картинках. Передаем в функцию train_on_batch сгенерированные изображения (gen_imgs), метки (labels) и массив нулей (fake)
d_loss = np.add(d_loss_real, d_loss_fake) / 2 # Получаем массив средних ошибок дискриминатора. Поэлементно складываем массивы d_loss_real и d_loss_fake и делим каждое значение пополам
# --- Train Generator ---
sampled_labels = np.random.randint(0, self.num_classes, batch_size).reshape(-1, 1) # Получаем массив случайных меток от 0 до 10 размерностью batch_size и решейпим его в размерность (batch_size, 1)
self.discriminator.trainable = False
g_loss = self.combined.train_on_batch([noise, sampled_labels], valid) # Получаем ошибку генератора. Передаем в функцию train_on_batch шум (noise), метки (sampled_labels) и массив единиц (valid)
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss)) # Plot the progress
if (epoch % save_interval == 0) or (epoch == epochs - 1): # Выводим/сохраняем изображения каждые save_interval эпох и в конце цикла
self.save_imgs(epoch, save_images)При загрузке датаcета из mnist в y_train добавляются метки, соответствующие изображению цифры. Т.е. рукописному изображению цифры 9 в x_train сопоставлена цифра 9 в y_train.
При выборе случайным образом индексов картинок размером batch_size выбираются сами картинки и соотвествующие им метки y_train.
imgs, labels = X_train[idx], y_train[idx]
По этой паре идет формирование нового batch_size картинок для тренировки дискриминатора. Дискриминатор тренируется на массиве реальных изображений (обозначены как valid) и сформированных генератором (обозначены как fake). В случае реальных изображений дискриминатор должен выдать 1, а в случае сформированных генератором — 0. При этом во время тренировки дискриминатора вместе с массивом изображений передается и вектор меток, который подмешивается к картинкам:
gen_imgs = self.generator.predict([noise, labels]) # Формируем массив изображений с помощью входной переменной generator
self.discriminator.trainable = True
d_loss_real = self.discriminator.train_on_batch([imgs, labels], valid) # Ошибка дискриминатора, обученного на реальных картинках. Передаем в функцию train_on_batch реальные изображения (imgs), метки (labels) и массив единиц (valid).
d_loss_fake = self.discriminator.train_on_batch([gen_imgs, labels], fake) # Ошибка дискриминатора, обученного на сгенерированных картинках. Передаем в функцию train_on_batch сгенерированные изображения (gen_imgs), метки (labels) и массив нулей (fake)После обучения дискриминатора запускается тренировка объединенной модели. При этом тренировка весов дискриминатора замораживается. Он в этом случает работает как классификатор, определяющий, насколько сформированное при тренировке генератора изображение отличается от оригинальных картинок, использовавшихся при тренировке дискриминатора.
Для тренировки генератора формируется случайным образом вектор меток размером batch_size и шум с нормальным распределением. Обе матрицы подаются на сборную модель для тренировки. При этом в комбинированной модели дискриминатор получит на вход картинку с выхода генератора, проинициализированную матрицей шума и метки.
Поскольку дискриминатор только что тренировался на паре оригинальная картинка + метка, то он будет производить классификацию полученного на вход изображения в паре с меткой. Грубо говоря, нейронная сеть дискриминатора, используя метку, будет сопоставлять сформированные генератором картинки с этой меткой с картинками только этого класса.
Подали, например, 9 в качестве метки, и сеть определяет, насколько сформированная генератором 9-ка хороша в сравнении с 9-ками от оригинальных изображений, на которых тренировался дискриминатор. Это некорректное описание работы нейронной сети, но оно упрощает понимание физики работы.
Если генератор на основании метки и шума сформировал изображение цифры низкого качества, то ошибка (loss) будет значительной. Нейронка будет продолжать тренировку, пытаясь подобрать веса генератора так, чтобы дискриминатор, натренированный на оригинальных картинках, признал результат его работы как valid, т.е. обманулся.
# --- Train Generator ---
sampled_labels = np.random.randint(0, self.num_classes, batch_size).reshape(-1, 1) # Получаем массив случайных меток от 0 до 10 размерностью batch_size и решейпим его в размерность (batch_size, 1)
self.discriminator.trainable = False
g_loss = self.combined.train_on_batch([noise, sampled_labels], valid) # Получаем ошибку генератора. Передаем в функцию train_on_batch шум (noise), метки (sampled_labels) и массив единиц (valid)Пример сформированных картинок в нужном порядке от 0 до 9. В случае GAN цифры отображались хаотичным образом. В случае CGAN можно управлять выводом сгенерированных чисел.
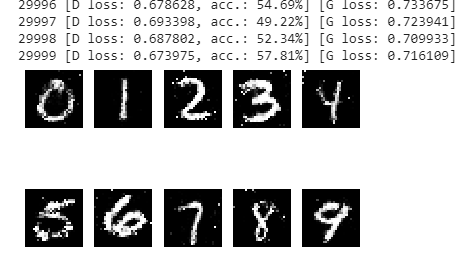
Поскольку слои и генератора, и дискриминатора Dense, то на результирующих изображениях цифр видны характерные белые точки на черном фоне. В случае со сверточными слоями либо в дискриминаторе, либо в генераторе фон был бы идеально черный, без случайных белых точек.
Работа AC-GAN в сравнении CGAN
В AC-GAN Дискриминатор имеет два выхода:
- Для классификации изображений (real или fake). Для этого используется Dense слой с одним нейроном. Функции потерь (loss) — binary_crossentropy. Точно также как в ранее рассмотренном C-GAN.
# real/fake output out1 = Dense(1, activation='sigmoid')(flat_img)
- Для определения, к какому классу относится изображение. Слой с размерностью num_classes для определения метки изображения. Функция потерь (loss) — categorical cross-entropy.
# class label output out2 = Dense(num_classes, activation='softmax')(flat_img)

Чтобы не сравнивать OHE (one hot encoding) меток класса с тем, что получено на втором выходе (для классификации классов), как делается обычно, можно сравнивать непосредственно номера классов. Для этого используется loss функция sparse categorical cross-entropy. Это даст такой же эффект, как в случае с loss в виде categorical cross-entropy, но убирает лишний шаг по преобразованию входных классов с помощью OHE.
При компиляции модели в Keras нужно будет передать в аргументах loss в таком виде:
opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss=['binary_crossentropy', 'sparse_categorical_crossentropy'], optimizer=opt)
Здесь обозначено, что для первого выхода будет применяться binary_crossentropy, а для второго — sparse_categorical_crossentropy.
flat_img = Flatten()(img) # Создаем слой Flatten() от слоя img # real/fake output out1 = Dense(1, activation='sigmoid')(flat_img) # class label output out2 = Dense(n_classes, activation='softmax')(flat_img) # define model model = Model(in_image, [out1, out2]) # compile model opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss=['binary_crossentropy', 'sparse_categorical_crossentropy'], optimizer=opt) return model
Генератор в AC-GAN выглядит так же, как в C-GAN — принимает на вход шум и класс меток. В нашем случае цифры от 0 до 9. Объединение выходов в коде выполнено через Concatenate() Keras:
# merge image gen and label input merge = Concatenate()([noise, label_embedding])
Если распечатать модель генератора из примера (сеть в примере сверточного типа):
plot_model(model, to_file='generator_plot.png', show_shapes=True, show_layer_names=True)
то она будет выглядеть так:

на входе — вектор шума и метки. На выходе — сформированное изображение рукописной цифры.
Объединенная модель принципиально ничем не отличается от уже рассмотренной в C-GAN. Принцип работы в части заморозки весов дискриминатора при тренировке общей модели такой же. В C-GAN при компиляции использовался loss=’binary_crossentropy’
self.combined = Model(inputs = [noise, label], outputs = valid, name = "CGAN") # Создаем полную сеть combined (входные данные: noise и label, выходные данне: val)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
self.combined.summary()В AC-GAN нужно использовать loss=[‘binary_crossentropy’, ‘sparse_categorical_crossentropy’], т.е. разные для двух выходов дискриминатора:
# compile model opt = Adam(lr=0.0002, beta_1=0.5) self.combined.compile(loss=['binary_crossentropy', 'sparse_categorical_crossentropy'], optimizer=opt)
В остальном все примерно то же самое, принципиальных различий нет. Детально можно посмотреть в коде из статьи.
Полезные ссылки
- How to Develop an Auxiliary Classifier GAN (AC-GAN) From Scratch with Keras — https://machinelearningmastery.com/how-to-develop-an-auxiliary-classifier-gan-ac-gan-from-scratch-with-keras/
- ACGAN Architectural Design — https://stephan-osterburg.gitbook.io/coding/coding/ml-dl/tensorfow/chapter-4-conditional-generative-adversarial-network/acgan-architectural-design